FJU Test Collection for Evaluation of
Chinese Text Categorization
By Yuen-Hsien Tseng, Feb. 1, 2004
http://www.lins.fju.edu.tw/~tseng/Collections/Chinese_TC.html
Introduction
Text categorization (or document classification) is a process of assigning
labels to documents according to the contents or topics of the documents.
The labels (classes or categories) usually come from one or more predefined
sets that reflect the knowledge structures intended to organize the documents.
Traditionally text categorization is carried out by human experts as
it requires a certain level of vocabulary recognition and knowledge processing.
As the amount of full-text documents rapidly increases in this digital age,
automatic ways of assigning labels to documents to assist human
experts become, in some cases, inevitable. Examples are
news dispatching and spam email filtering. Both require labeling
bulk messages in a short period of time according to the message contents,
a task that is not easily done by human efforts.
Automated text categorization also helps human categorizers in traditional
tasks.
By suggesting possible classes for each unlabelled document,
a machine classifier relieves the burdens of reading full-text documents
and memorizing every class definition in a knowledge structure,
both are required by a categorizer for the classification task.
For novices in such tasks, this way of having a machine classifier seems
to have an experienced colleague as a guide. Thus the training cost can
be reduced and the period of getting acquainted with the task can be
shortened, allowing more people involved in this knowledge organization and
value-added task.
But how well can a machine classifier perform?
It is a research interest and in fact a great need to evaluate the
effectiveness of automated text classification to justify its advantages.
There have already existed several test collections for evaluation of
automatic text categorization technologies. For examples: Reuters 21578,
OHSUMED, and 20NG. All of these test collections are in English.
It is needed to have some Chinese test collections for direct evaluation
of Chinese processing techniques in automatic text categorization.
Sources of the Test Collection
The test collection provided here is originated from a several-years long
digitization project of SCRC
(Socio-Cultural Research Center) at
Fu Jen Catholic University.
The digitization project is mostly sponsored by the National Science Council,
Republic of China.
The source of the test collection comes from the news broadcasts of
Mainland China's radio stations between 1966 and 1982.
These broadcasts were transcribed and labeled by hands in
manuscript papers on-site or by first recording the broadcasts and
then transcribed afterwards.
This material was used to reveal what happened in Mainland China
during the Cultural Revolution by SCRC, which formerly situated in
Hong Kong and published a well-known periodical, the CHINA NEWS ANALYSIS.
In year 2000-2001, under the digitization project, SCRC has 42371
manuscripts key-in manually for the preservation and better use
of this material. Among them, 30710 manuscripts have category labels
and dates.
Only a part of the manuscripts is included in this test collection
according to the following guidelines:
- Each category must have documents in the training set and in the test
set so that an effective training and testing of a machine classifier
is possible.
- The training documents predate all the test documents to reflect
the ordinary use of an operational machine classifier.
Contents of the Test Collection
- Document Set
- There are totally 28011 documents, divided into a training set
(19901 documents) and a test set (8110 documents).
- The documents dated back from 1966/01/01 to 1982/12/26.
- Training documents are from 1966/01/01 to 1976/12/31.
- Test documents are from 1977/01/01 to 1982/12/26.
- Since the documents come from the manual transcription of on-site news
broadcasts, missing words or even snippets are not un-common
in the documents.
- Categories
- There are totally 82 categories in the above documents.
Category definitions may change slightly over time or interpreted
differently among different categorizers. Only those categories that
occur both in the training set and test set are selected.
- A list of the category descriptions in Chinese keywords, provided
by SCRC, is included in this collection distribution (file: CatDesc.doc).
- Original category names are most in English and digits,
only 3 Chinese characters are used in this collection's categories.
The 3 characters are ¤ĺ (Culture), ¶Ç (Biography), and Ąv (History).
They are encoded into Cu, Bi, and Hi, respectively, for the convenience
of non-Chinese users.
Note:
- 'Hi' only occur in the category names 'P5Hi'. But 'P5Hi' can not
be found in CatDesc.doc. After browsing some of the P5Hi's documents,
I wonder 'P5Hi' should be 'P5-10' (History of Chinese Communism).
- All the categories that are not in the description list
are: 'E1a', 'E36a', 'HK', 'P10a', 'P53', 'P5Hi'.
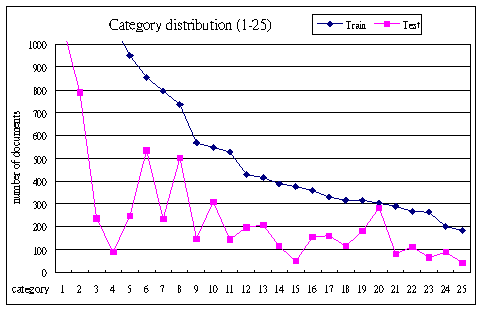
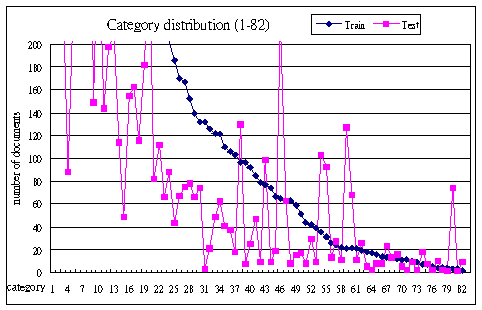
- Some category distributions are listed below:
| No. | Cat | Train | Test |
|---|
| 1 | P52 | 3985 | 1073
| | 2 | P10 | 1903 | 788
| | 3 | Cu4 | 1115 | 236
| | 4 | E34 | 1085 | 88
| | 5 | E3 | 950 | 248
| | 6 | P5 | 854 | 536
| | 7 | E6 | 797 | 234
| | 8 | P4 | 736 | 501
| | 9 | E5 | 569 | 149
| | 10 | E36 | 548 | 310
| | 11 | Cu31 | 529 | 144
| | 12 | E53 | 430 | 198
| | 13 | P73 | 417 | 208
| | 14 | E10 | 390 | 114
| | 15 | Cu71 | 376 | 49
| | 16 | P72 | 361 | 155
| | 17 | P1 | 330 | 163
| | 18 | P6 | 317 | 116
| | 19 | E1 | 316 | 182
| | 20 | E4 | 305 | 283
|
|
| No. | Cat | Train | Test |
|---|
| 63 | E38 | 18 | 5
| | 64 | P10a | 17 | 2
| | 65 | P11 | 16 | 8
| | 66 | P5Hi | 14 | 8
| | 67 | P33 | 13 | 23
| | 68 | Bi | 13 | 13
| | 69 | Cu51 | 12 | 16
| | 70 | Cu91 | 11 | 5
| | 71 | P51 | 11 | 2
| | 72 | E9 | 10 | 9
| | 73 | E39 | 9 | 2
| | 74 | E83 | 7 | 18
| | 75 | E1a | 7 | 7
| | 76 | Cu73 | 5 | 2
| | 77 | HK | 4 | 10
| | 78 | E1-3 | 4 | 2
| | 79 | E31 | 4 | 1
| | 80 | E1-4 | 3 | 74
| | 81 | P9 | 3 | 1
| | 82 | P53 | 2 | 9
|
|
 |
 |
- Label Assignment
- Each document was labeled 1 to 4 categories, but mostly only 1 label.
The average number of labels per documents is 1.035 categories
for the training set and 1.007 for the test set.
- Since the documents spread over 17 years, consistency of the
label assignment may somewhat be a problem. But since almost
all human-labeled collections have the consistency problem
(the inconsistency rate can range from 10% to 40%),
users of any test collections should bear this in mind
in interpreting their evaluation results.
Download
To get this collection,
click here and you will be prompted with a form that
needs your following information:
- First Name:
- Last Name:
- Title:
- Affiliation:
- Email:
- Home page (if any):
- To be listed in the Request List: Yes/No
- Other comments:
Upon receiving this request, a pair of username and password will be
included in a reply message for downloading the test collection.
Request List
Those who have requested this test collection will be listed here for 2 reasons:
- To allow direct or indirect contact and sharing of the experiences of using
this collection among those who have requested it.
- To have a chance to evaluate the usefulness of this collection, based on
the copies distributed among intended users, as it is created for research
purposes supported by the NSC, Taiwan, R.O.C..
Here are the requests:
- Yuen-Hsien Tseng.
Yuen-Hsien Tseng and William John Teahan,
"Verifying a Chinese Collection for Text Categorization,"
to appear in the Proceedings of the 27th International ACM SIGIR Conference
on Research and Development in Information Retrieval -
SIGIR '04, July 25 - 29 Sheffield, U.K., 2004.
- More ...
Acknowledgement
- SCRC provides all their digital collections.
Special thanks are to ĂöŞĂ±G former Chair of SCRC, ¨fŻ«¤÷ Chair,
and ±dŞÚµ×, §ő«C¬Â, ľG©ú˝ĺ for their help during these years.
- National Science Council sponsors most of the expenditure to
create this test collection. Related grants are:
NSC 88-2418-H-001-011-B8908, NSC 88-2418-H-001-011-B9003,
NSC 88-2413-H-030-017-, and NSC 92-2213-E-030-017-.