|
文件內容自動分類
緣由與目的:
- 文件分類 是根據文件內容或主題給定類別的工作。例如,
新聞文件可按其報導的內容,給予「政治」、「外交」、「娛樂」、
「運動」等類別。
通常,這些類別都是事先定義或選定,以符合管理者的需求與期望。
而給定類別的工作,傳統上都由人工閱覽文件,根據其主題大意,
給予適當的類別標示。
- 文件分類的目的,在對文件進行分門別類的加值處理,
使得文件易於管理、利用。
文件分類可將非結構化的資料,轉換成結構化的資訊,是資訊組織、
主題分析與知識管理的重要工具。
- 近年來,拜資訊技術普及運用之賜,
各個企業與機構的數位文件不斷快速累積,數量大到難以有效的管理與利用,
文件分類的需求也就因應而生。
為此,如何利用自動化的技術,快速有效的協助人工分類,
來應付大量暴增的分類需求,是現今資訊服務與知識管理的重要課題。
- 文件分類自動化後,會帶出更新、更便利的應用方式,除了提供館藏瀏覽
(collection browsing)、主題檢索(topic-based retrieval)、文件管理
(歸檔、調閱、分享)外,還可應用在網頁過濾、電子郵件過濾、資訊選萃
(SDI, Selected Dissemination of Information)、資訊配送
(information filter or routing)、甚至是文字探勘(text mining)、
新知發掘(knowledge discovery)、知識管理(knowledge management)等領域。
跟文件檢索一樣,舉凡牽涉到非結構化文件的處理,都有文件分類的應用。
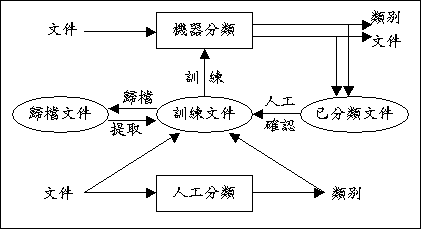
- 文件分類,需要瞭解文件的主題大意,才能給定類別,
因此是相當高階的知識處理工作。要將文件分類自動化,
必須先整理出分類時的規則,電腦才能據以執行。
然而,多數的分類工作,其分類規則通常難以用人工分析歸納獲得。
因此,機器在做自動分類之前,還必須加以訓練,
使其自動學習出人工分類的經驗與知識。
- 現今自然語言理解的技術,還無法讓電腦瞭解任意的自由文句。
因此機器在做文件分類時,常將文件分解成一個個語意較小的單位,
通常為文件的關鍵詞彙,或稱「特徵詞彙」,
再從這些詞彙與類別中找出對應的關係。
有時分類的問題,簡單到只要文件的某個欄位中出現什麼特徵詞,
就分到什麼類別去。但大部分的情況都沒那麼簡單。
例如,「文化大革命」這個類別,如何界定哪些詞彙一定是屬於這個類別,
哪些不是?顯然某些詞彙對這個類別較重要(比較有鑑別力),
其他的則較不重要(比較不具鑑別力)。
如何決定這些詞彙在每個類別的權重,正是機器學習(Machine Learning)
可以派上用場的地方。
- 應用機器學習與自然語言處理的理論與方法,經過數年的文件自動分類研究、
實驗與調整,我們的文件分類成效已達人工分類水準,並且可同時進行上千個
類別、上千篇文件的每日即時分類。
目前為止,這些發展出來的技術與方法,已應用於數種產業領域,每日進行
例行的文件自動分類任務。
分類流程圖:
系統特色:
- 可處理多種文件格式(Word, PDF, XML, HTML, TXT),
以及中、英、繁、簡字體。
- 視窗使用介面,可動態編輯、修改分類架構。
- 支援同一篇文件多重分類架構、多重類別的多重分類要求
(multi-taxonomy, multi-class, multi-label classification)。
- 使用單位僅需提供分類範例,及分類架構,即可開始文件自動分類。
- 可提示類別特徵詞彙,以分析或瞭解文件分類過程。
- 可顯示主題類別間的相似度,以分析或瞭解分類架構是否設計得宜。
- 可自動提示文件主題分佈,建議分類架構的設計。
- 長文件自動摘要,以準確進行文件分類。
- 提供完整 API,支援 Windows, Solaris, Linux, AIX 平台,系統整合簡易。
- KNN(K-Nearest Neighbor)與 SVM(Support Vector Machine)分類器
(classifier),是目前被認為最好的兩種文件分類方法。
我們提出一種改進技術,使得即便用了最好的分類器,仍然還有機會改進
文件分類的成效。
範例:
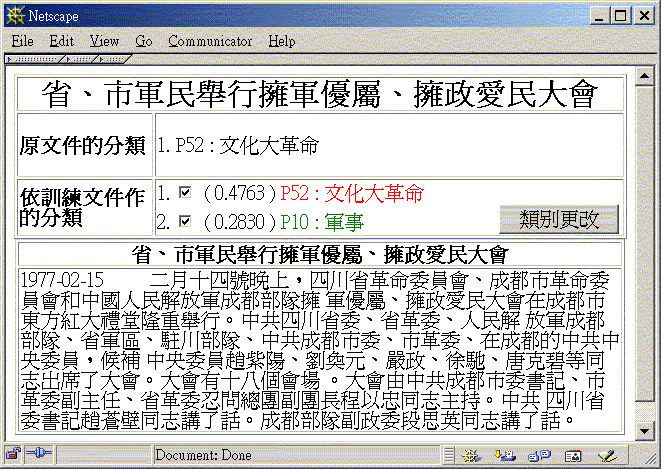
量化成效評估:
-
下面的範例顯示,我們提出的方法,在只有少量訓練文件可用時,
可有效改進原分類方法的分類成效。
-
表中 KNNd, KNNt 與 SVMd, SVMt 為我們發展出來,改進 KNN 與 SVM 的分類方法。
Sample 這一欄,表示用以訓練分類器的文件篇數,為原始訓練文件
篇數的百分比率。
-
新聞文件(News)分類成效(共 12 類,訓練文件 100%=644 篇,
測試文件 270 篇)。
Table 1(a) MicroF of the collection News.
|
Sample | KNN | KNNd | KNNt | SVM | SVMd | SVMt
| |
5% | 0.47 | 0.51 | 0.48 | 0.40 | 0.45 | 0.41
| |
10% | 0.58 | 0.64 | 0.60 | 0.57 | 0.60 | 0.59
| |
20% | 0.70 | 0.67 | 0.70 | 0.63 | 0.62 | 0.68
| |
40% | 0.72 | 0.72 | 0.72 | 0.63 | 0.65 | 0.71
| |
100% | 0.79 | 0.78 | 0.77 | 0.71 | 0.72 | 0.74
|
Table 1(b) MacroF of the collection News.
|
Sample | KNN | KNNd | KNNt | SVM | SVMd | SVMt
| |
5% | 0.30 | 0.35 | 0.28 | 0.19 | 0.29 | 0.27
| |
10% | 0.32 | 0.49 | 0.40 | 0.31 | 0.42 | 0.42
| |
20% | 0.50 | 0.54 | 0.52 | 0.45 | 0.49 | 0.54
| |
40% | 0.62 | 0.61 | 0.65 | 0.49 | 0.55 | 0.61
| |
100% | 0.73 | 0.76 | 0.70 | 0.64 | 0.66 | 0.69
|
網頁描述文件(WebDes)分類成效(共 26 類,訓練文件 100%=1190 篇,
測試文件 496 篇)
Table 2(a) MicroF of the collection WebDes.
|
Sample | KNN | KNNd | KNNt | SVM | SVMd | SVMt
| |
5% | 0.64 | 0.69 | 0.67 | 0.67 | 0.68 | 0.67
| |
10% | 0.69 | 0.70 | 0.70 | 0.71 | 0.70 | 0.72
| |
20% | 0.67 | 0.73 | 0.74 | 0.65 | 0.73 | 0.75
| |
40% | 0.75 | 0.75 | 0.76 | 0.78 | 0.77 | 0.79
| |
100% | 0.78 | 0.78 | 0.78 | 0.78 | 0.78 | 0.78
|
Table 2(b) MacroF of the collection WebDes.
|
Sample | KNN | KNNd | KNNt | SVM | SVMd | SVMt
| |
5% | 0.32 | 0.43 | 0.39 | 0.35 | 0.43 | 0.37
| |
10% | 0.38 | 0.46 | 0.45 | 0.42 | 0.49 | 0.47
| |
20% | 0.45 | 0.49 | 0.51 | 0.46 | 0.52 | 0.54
| |
40% | 0.55 | 0.57 | 0.58 | 0.61 | 0.63 | 0.61
| |
100% | 0.58 | 0.63 | 0.61 | 0.67 | 0.66 | 0.67
|
由上面的數據可知:
- 訓練文件越多,分類成效越好。
- 我們提出來的改進方法,在訓練文件越少時,改進的成效越明顯。
- 訓練文件夠多時,再怎們提整參數、運用改進策略,成效有限。
必須根本的改變分類方法,才有可能大幅度地提昇成效。
- 不同的分類方法在不同的文件集、不同的分類問題上,會有不同的表現。
例如:在上面新聞文件的例子中,KNN 比 SVM 好,
但在網頁描述的文件上則是SVM比KNN好(MicroF雖相同,但MacroF方面SVM比KNN好)。
- 相同的分類方法,在不同的文件分類問題,其成效也會不同。
例如,上面的網頁描述文件
分類數據顯示,SVM 的 MicroF 有 0.78 的成效,但在新聞文件中,
只有 0.71 的成效。
- 單獨一種分類方法,在單獨一種分類文件集上獲得的成效改進,
難以保證其在另一種分類文件集上,也會有相同好的成效。
其他文件集的分類成效:FJU CTC and Reuters-21578
FJU CTC文件集可從
http://www.lins.fju.edu.tw/~tseng/Collections/Chinese_TC.html
取得。
Reuters-21578可從
http://www.daviddlewis.com/resources/testcollections/reuters21578/
取得。
Table 3(a) MicroF of the collection FJU CTC and Reuters-21578.
| Collection | Model | All docs. | S<1.0 | S<0.8 | S<0.6
| | FJU CTC | VSM | 0.4383 | 0.4412 | 0.4494 | 0.4504
| | BM11 | 0.4605 | 0.4679 | 0.4787 | 0.4788
| | Reuters-21578 | VSM | 0.8192 | 0.8170 | 0.8161 | 0.8156
| | BM11 | 0.8240 | 0.8253 | 0.8247 | 0.8232
|
Table 3(b) MacroF of the collection FJU CTC and Reuters-21578.
| Collection | Model | All docs. | S<1.0 | S<0.8 | S<0.6
| | FJU CTC | VSM | 0.2881 | 0.2916 | 0.2844 | 0.2844
| | BM11 | 0.3177 | 0.3236 | 0.3182 | 0.3080
| | Reuters-21578 | VSM | 0.3681 | 0.3676 | 0.3603 | 0.3428
| | BM11 | 0.4211 | 0.4206 | 0.4072 | 0.3823
|
表 3 中的 S<1.0 表示刪除相似度為 100% 的文件,即重複文件,
S<0.8 表示刪除相似度為 80% 的文件,
S<0.6 表示刪除相似度為 60% 的文件,
詳細說明請參考 [Tseng and Teahan, SIGIR 2004] 文章。
質化成效評估:
-
假如沒有機器分類,那麼人工就要仔細閱讀、分析該篇文件,
然後為了標出類別,還要熟悉各個類別的意義及其在分類架構中的相對範圍。
假若使用的分類架構很大,例如有上百個類別,一一記住每個類別的內容與範圍,
以比對出文件的類別,常常需要熟練且具備耐心的人員才能勝任。
-
有了機器分類後,自動分類的結果對人力而言,可以視為是一種分類提示,
對減輕人力分析文件、決定類別的努力,有相當大的助益。
-
尤其對新手而言,此種分類提示猶如有專家在旁協助,分類工作將更快能步上軌道。
-
實際應用上,自動分類可以節省一半以上的人力。
-
自動分類也可以縮短分類人力的職前教育訓練成本與在職者的熟悉摸索期間。
因此,人員流動造成的損失,可大幅降低。
相關著作:
- Yuen-Hsien Tseng and William John Teahan,
"Verifying a Chinese Collection for Text Categorization,"
to appear in the Proceedings of the 27th International ACM SIGIR Conference
on Research and Development in Information Retrieval -
SIGIR '04, July 25 - 29 Sheffield, U.K., 2004.
- Yuen-Hsien Tseng and Da-Wei Juang, "Document-Self Expansion for
Text Categorization," Proceedings of the 26th
International ACM SIGIR Conference on Research and Development in
Information Retrieval - SIGIR '03, July 28 - Aug. 1, Toronto, Canada,
2003, pp.399-400.
- 曾元顯, "文件主題自動分類成效因素探討",
「中國圖書館學會會報」, 2002 年 6 月, 第 68 期, 頁 62-83.
- 曾元顯, "數位文件之資訊組織與主題分析自動化之技術與應用",
「台北市立圖書館館訊」, 2002 年 12 月, 第 20 卷, 第 2 期, 頁 23-35.
相關計畫:
- 曾元顯, 「少量訓練文件之自動分類研究」, 國科會92學年度研究計畫報告,
NSC 92-2213-E-030-017-。
Established on June 1, 2001, last modified on April 15, 2004 by
Yuen-Hsien Tseng
<tseng@lins.fju.edu.tw>
|