
圖一:相關詞提示範例一
曾元顯
輔仁大學圖書資訊學系副教授
Yuen-Hsien Tseng
Associate Professor
Department of Library and Information Science
Fu Jen Catholic University
Email: tseng@blue.lins.fju.edu.tw
林瑜一
台灣師範大學
Yu-I Lin
National Taiwan Normal University
http://blue.lins.fju.edu.tw/~tseng/papers/crystal/crystal.htm
Oct. 24, 1998
Accessed times
本文介紹我們以向量空間檢索模式、N-gram索引法以及關鍵詞自動擷取技術開發的「模糊搜尋」、「相關詞提示」與「相關詞回饋」的檢索功能,並評估其整合在既有OPAC系統上的應用成效。我們採用線上問卷調查法、檢索記錄檔分析法以及資訊檢索領域常用的查全率、查準率等指標來衡量使用者的反應以及檢索成效。主要的結果如下:一、新的檢索功能使用比例高,且此情形與受訪者對這些功能的熟悉程度無關,但與受訪者無法精確表達查詢條件有關;二、多數受訪者能遵循相關詞提示、繼而模糊搜尋、之後繼續採用模糊搜尋或相關詞回饋的最有利過程進行資料查詢,而且此現象也與受訪者對這些功能的熟悉度無關;三、不論受訪者是否能夠精確表達查詢條件,新的檢索功能沒有比傳統欄位式檢索系統提供更佳的檢索結果滿意度,惟在找到資料的情形上表現較好;四、多數受訪者(80%)對於系統自動擷取的詞彙,偶有不合理的情形(10%)多可接受;五、在理想的檢索環境下,相關詞提示與相關詞回饋比用模糊搜尋直接查詢資料庫的成效更佳,分別可提昇38.2%及29.1%的檢索成效。
Abstract
This
paper introduces three retrieval functions developed based on
the vector space retrieval model, N-gram indexing model, and an
automatic keyword extraction technique. These retrieval functions
are known as fuzzy search, term suggestion, and term relevance
feedback. Evaluation of these new functions integrated in an OPAC
system is performed through the approaches of online questionnaires,
search log analysis, and recall and precision rates. The major
results are: (1) The new retrieval functions have high usage rates,
which is independent of the users'
familiarity with the functions, but is related to the inability
to express queries exactly. (2) Most users follow the best retrieval
steps by first using term suggestion, and then fuzzy search, and
then continuing on fuzzy search or changing to term relevance
feedback, which is also independent of the users'
familiarity with these functions. (3) No matter whether users
can express their queries exactly or not, new retrieval functions
do not provide better retrieval satisfaction than traditional
Boolean search. However, they do perform better in providing better
results. (4) The 10% illegal suggested terms, automatically extracted
by the system, are acceptable by 80% users. (5) In ideal environments,
term suggestion and term relevance feedback perform better than
fuzzy search with performance increase by 38.2% and 29.1%, respectively.
關鍵詞:資訊檢索、成效評估、模糊搜尋、相關詞提示、相關詞回饋
Keywords: information retrieval, performance evaluation, fuzzy search, term suggestion, term relevance feedback
目前大部份圖書館的線上公用目錄(Online
Public Access Catalog, OPAC)系統主要是以布林邏輯(Boolean
Logic)精確比對的模式提供書目查詢。此種模式提供檢索條件之間的交集(AND)、聯集(OR)、差集(NOT)的運算,甚至於後切截比對(truncation)以及檢索詞之間鄰近條件(proximity)的過濾功能,對專業的檢索者而言,這些功能其實是相當有效的檢索工具。然而由於一般的使用者對布林邏輯的運用較不熟悉、檢索結果未能依照符合程度排序、以及檢索字串要求精確無誤等原因,布林邏輯的比對模式易導致較高的檢索失敗率(search
failure)與資訊溢檢率(information
overloading)[1-2],從而造成書目檢索系統不易使用的情形
[3-4]。
針對此問題,已有一些先進的檢索技術運用在OPAC的研究,如國外的Cheshire、SPRILIB、CITE、OKAPI等系統
[5],以及國內利用CSMART改進中文OPAC系統的努力
[6-7]。過去這一兩年,我們也以輔仁大學圖書館提供的書目資料,逐步開發了「模糊搜尋」(即「近似字串比對」)、「相關詞提示」、「相關詞回饋」、「相關程度排序」等功能,並整合在既有的OPAC系統上,期使OPAC檢索系統除原有的跨欄位布林檢索外,亦能具有允許冗字、錯字、資料誤植、資料記載不一致、中英文夾雜、自由詞彙、以及近似自然語言檢索的功能
[8-9]。
本篇文章之目的,即在瞭解「模糊搜尋」、「相關詞提示」、「相關詞回饋」、「相關程度排序」等技術整合在OPAC上的應用成效,以做為線上檢索系統進一步發展的改進參考。具體目標如下:
第一項目標在瞭解新的檢索功能,與傳統欄位式(布林邏輯)查詢方式並存時,被利用的狀況。一項新的功能,如果使用率偏低,則其實用價值不高。此種情況,可以考慮移除此項功能以減低系統的負擔,或是加強宣導與說明,提醒使用者善加利用。吳美美的一項研究顯示
[10],在調查的123次檢索中,使用者全部都使用不需加任何符號的逐字檢索功能,對另外三種需在檢索詞後加上特殊符號才能使用的特殊檢索功能─即「完全符合」、「向後切截」與「近似檢索」─都沒有人利用。其中「近似檢索」與本文描述的近似字串檢索功能相近,顯然新的檢索功能或甚至更好的檢索功能,可能因使用介面的因素,還是會有被使用者忽視的可能。
新的檢索功能比對相關文件的方式(近似字串比對,檢索結果按近似程度排序)與傳統功能不同(精確字串比對,檢索結果只有符合、不符合的區別),使用者將檢索需求表達成檢索條件的方法也不同(系統可提示相關詞,相對於使用者自己輸入必要的檢索詞)。從初步的結果分析,新的檢索功能,在很多情況下會比傳統的檢索功能有效,尤其對那些檢索條件不能精確表達、或檢索需求以傳統方式不易表達的查詢,可以達到相當程度的檢索效果。因此第二項目標,希望就這方面,瞭解實際狀況與理想狀況下,新的功能可否發揮預期的效果,其發揮效益的情況如何。第三項目標則希望反映出使用者使用後的感受,從其觀點,來瞭解檢索功能有否發揮效果,以及一些系統設計上的妥協,是否被使用者接受。
過去一段時間,我們一直在發展新一代的線上檢索技術,尚未就其成效進行正式的評估。我們認為本文所進行的研究,一方面有助於瞭解系統實際使用時的成效,再方面也可做為進一步發展線上檢索系統的改進參考,具有實用與研究的價值。
本文組織如下:下一節將介紹我們發展的全文檢索系統、其設計上的考量與細節,並舉例說明實際應用的情況;第三節說明我們採用的研究方法、考慮的因素;第四節就採用的線上問卷調查法與檢索記錄檔分析法,報告並分析結果;第五節則以有經驗的檢索者實際試驗,對檢索成效以查全率及查準率作量化的比較;最後,我們就以上的研究發現作綜合評論,並對未來的發展提出一些看法。
傳統的檢索系統主要以搜尋樹(search
tree)的資料結構建構索引檔,如二元搜尋樹或B
樹
[11]。此種結構除允許字串的快速精確比對外,也允許快速的右(後)切截比對運算。如輸入字串「經濟」,可比對出「經濟成長」、「經濟發展」、「經濟學」等,但無法有效比對出「總體經濟」、「區域經濟」等左邊有字的左(前)切截比對運算。在檢索詞的建構方面,英文詞以空白隔開,在選詞上較無問題,中文詞無明顯斷詞符號,傳統上大多以詞庫比對的方式來建構。亦即利用既有的電子詞庫或人工建立維護的詞庫,比對文件中的字串,若文件中的字串出現在詞庫中,就將此字串建構為描述此文件內容的索引詞,爾後使用者以此字串查詢時,即可查得此文件。將此索引詞以搜尋樹建構後,可提供「關鍵詞」的檢索功能。但詞庫中沒有收容的詞,或進行文件斷詞時沒有斷出來的文件字串,就無法提供使用者用以檢索到相關的文件。因此,即使有全文(full
text),卻不能下任意的自由詞(free
text)來檢索,此乃傳統檢索系統的一些限制。
改進檢索成效的方法可透過權威檔、標題表、索引典等資料的輔助。事實上這些資料不僅對傳統的檢索系統有幫助,對現有及未來的自動化全文檢索系統也有相同的貢獻。只不過建構此種完善的輔助資料需要相當多人工的資訊分析與組織,在此我們僅討論文件自動處理所能提供的各種檢索功能。
利用其他自動化技術開發較為先進的檢索系統已發展一段時間,國外著名的系統有SMART
[12]、INQUERY
[13]等,國內亦有免費可取得的系統如CSMART
[14]、GAIS
[15],而且也有運用到圖書館書目查詢上的例子
[16]。不過為了教學、研究與功能擴展上的便利,我們還是自行發展了一套目前名為水晶(CRYSTAL)的全文檢索系統。
一、檢索功能
一個檢索系統大抵可以由其索引詞模式、檢索模式、及索引檔結構來瞭解及預測其表現。底下就這些項目分別說明水晶檢索系統的製作方法與提供的功能。
索引詞模式是檢索系統建構索引詞所依據的方法,它關係到系統比對查詢字串的能力。如前所述的傳統檢索系統以詞庫比對法斷出索引詞,則可稱為「以詞彙為主」(word-based)的索引詞模式。在中文系統中,如詞庫更新不及、或涵蓋範圍不足,會有上述無法找到資料的情形。因此,中文系統中亦有「以字元為主」(character-based)的索引詞模式,以解決維護詞庫的問題。但此模式對短的檢索詞成效較差,如檢索詞「中國」會索引成「中」及「國」,因此雖然會比對到含「中國」的文件,但也會比對到含「國中」或「開發中的國家」等文件,因為它們都含有「中」及「國」的索引詞。第三種索引詞模式為「N-gram」索引法
[17]。N-gram為文件中任意N個連續字元,如「中國社會」此一字串,當N為2時將可產生「中國」、「國社」、「社會」三個索引詞。如此可排除或降低「字元法」中類似「中國」與「國中」的字串順序問題,也可省去「詞彙法」中維護詞庫的煩惱。水晶檢索系統裡對中文採用的是1-gram及2-gram的索引法,亦即一個字串中,其個別的字元與任意相鄰的兩個字元都是可檢索的索引詞;對英文則採用1-word及2-word的索引策略,亦即將英文字串中個別的詞彙做完停用字(stop
word)處理及詞幹(stemming)處理後,將此詞彙(1-word)及字串中任意相鄰的兩個處理過的詞彙(2-word)都建成索引詞。如「information
retrieval systems」一詞將產生「inform」、「retriev」、「system」、「inform
retriev」及「retriev
system」五個索引詞。其中停用字處理是將無意義的詞刪除,如「the」、「of」、「to」等,而詞幹處理的目的則降低英文詞類變化對檢索比對的干擾,如「retrieve」、「retrieval」、「retrieving」都被處理成「retriev」,因此三者可互相比對獲得結果。當然,N-gram中的
N也可以取大一點,以加強字串順序的限制能力,然而N越大,可能的索引詞越多,造成系統儲存與處理的負擔,一般認為中文系統用1-gram及2-gram即可提供足夠的檢索成效。以水晶檢索系統應用在輔大356,000書目資料為例,共產生228,246個中文及237,022個英文索引詞,經刪除出現頻率低於3次的中文2-gram及英文2-word
後,還有79,244個中文及120,410個英文索引詞。
檢索模式是系統比對檢索條件與相關文件的依據。傳統作法大多採用「布林模式」,亦即文件內容符合檢索詞之間的布林運算者才取出,不符合者即捨去。布林模式有速度快、檢索者可完全控制檢索過程並預測檢索結果等優點,對需求明確的檢索(如明確的作者名、題名)非常有效。相對的它也有:結果沒有依照符合程度排序、一般使用者較難以此表達複雜查詢條件等缺點。另一種常看到的檢索模式為「向量模式」,藉由轉換文件及查詢語句到向量空間後,在此空間中比對查詢條件與文件的相似度,常用的相似度運算為餘弦夾角(cosine)
[18]。例如,「李遠哲院長」及「李院長遠哲」兩詞若以1-gram及2-gram建構索引詞,並以詞頻做為索引詞的值,那麼以(李,遠,哲,院,長,李遠,遠哲,哲院,院長,李院,長遠)為維度,則第一個詞的向量為(1,
1, 1, 1, 1, 1, 1, 1, 1, 0, 0)而第二個詞的向量為(1,
1, 1, 1, 1, 0, 1, 0, 1, 1, 1)。此兩向量餘弦夾角為7/9
= 0.78,表示兩向量在最高值為1的度量中,相似度為0.78。由此例可知,向量模式可允許使用者輸入任意字串,查詢時不必受資料誤植、錯字、冗字的限制,因此可概略稱為「近似字串查詢」、「容錯查詢」、或是「模糊搜尋」(fuzzy
search)。由於向量模式亦可接受完整的自然語句查詢,雖不懂得檢索者真正的語意,也可由此查得資料,因此亦可概略稱為「近似自然語言查詢」或「自然語言查詢」。另一種檢索模式為「機率模式」,藉由一些機率上的假設,將查詢詞彙與相關文件的不確定性,以機率描述並加以運算
[19]。此模式亦可做到向量模式的查詢效果,兩者不同的地方在基本的假設與運算的模式。水晶檢索系統裡採用的是向量模式(但相似度運算並非餘弦夾角),因為它較為單純,而且此模式在國際的資訊檢索競賽TREC會議上,也有良好的表現
[20]。因此在輔大的書目檢索系統裡,使用者可以輸入「"Find
books about public library services for children and young adults"」、「基本物理學導論概論原理入門」或「電視廣告對兒童的影響」等類似的查詢條件。
好的索引檔結構除可加快檢索的速度外,亦可影響檢索的成效。組織索引檔結構的方式主要有「反向索引檔」(inverted
file) [21]、「特徵檔」(signature
file)
[22]、「隱含語意索引法」(latent
semantic indexing)[23]
以及一些特殊的「搜尋樹」。在「反向索引檔」裡,記錄的是每個索引詞及其出現文件的編號,因此可從此索引檔直接取得包含某索引詞的所有文件。「特徵檔」則是將文件中的文字作特殊的編碼,使每個文件變成0與1組成的特徵向量,檢索時通常需要兩個階段,第一階段經由特徵檔的運算,過濾掉不可能的文件,第二階段再把一些誤引(false
drop)的文件過濾掉而得到真正的檢索結果。因此特徵檔的特色在於可加快大量非相關文件的過濾,得到的結果,可作進一步的分析、再過濾或直接運用。特徵檔的索引建構速度比起反向索引檔要快許多,其對新進文件的索引建構工作,亦即「漸進式索引」(incremental
indexing)的功能,在製作上也較為簡易。「隱含語意索引法」則是一種運用向量空間運算縮減索引詞維度,並關連相關文件的方法。此方法一開始先建構一個以索引詞為列、文件為行,以詞頻或其他統計資料為值的矩陣。經特異值分解(Singular
Value Decomposition, SVD)運算後,取得一個跟原矩陣特性近似,但維度較小的轉換矩陣(transform
matrix),或稱為檢索矩陣。文件都以此轉換矩陣轉換到另一個縮減的向量空間,檢索時也將檢索條件作相同的轉換處理,再以前述的餘弦夾角運算相似度。隱含語意索引法的特色在於文件經過轉換後,相關的詞彙會經由文件所包含的內容而產生關連。例如,假若某些文件包含「patient」、「doctor」、「surgeon」等詞,而某些文件包含「patient」、「doctor」、「physician」等詞,那麼「surgeon」與「physician」兩詞即使不曾在同一份文件出現過,也有了關連。當使用者輸入「surgeon」時,包含「physician」的文件也會以較小的相似度跟著出現
[24]。至於以「搜尋樹」建構索引檔的方法,有前面提過的B
樹以及PAT樹等等。尤其是PAT此種樹狀結構,可以有效的做到後切截檢索、鄰近字串檢索、範圍查詢、最常出現的字串檢索,以及常規式檢索(regular
expression search)等功能,非常適合字典或辭典等較少更新的靜態資料庫
[25]。水晶檢索系統裡採用的是反向索引檔,因為它簡單、有效,而且是大部份商業以及實驗系統所採用的方式。同樣以輔大35萬筆書目資料為例,此索引檔的大小約原資料量的1.4倍,為減輕檢索時讀取索引檔的負擔,我們將索引檔以雜湊函數(hash
function)[26]
分開成數千個檔案,只有跟目前檢索詞相關的索引才會被讀進記憶體,而不用將20萬個索引詞全部讀取進來,如此可大幅降低檢索時檔案讀取的時間。此外,水晶檢索系統也提供「漸進式索引」的功能,使得每日新增的書目資料加入檢索系統時,不必對所有的書目資料重作索引,只需對新增的資料作索引,再加入原索引檔中即可。如此可免除不必要的重複運算,大幅減輕系統的負擔。
除此之外,水晶檢索系統較特殊的地方是其關鍵詞自動擷取模組,此模組可從文件資料庫中擷取統計上重要的詞彙,作為「相關詞提示」(term
suggestion)及「相關詞回饋」(term
relevance feedback)的功能
[27-28]。資訊檢索中,檢索的成效非常倚賴使用者所下檢索詞的品質,而檢索詞的品質通常可以藉由「擴展」(expanding)來增進。此種額外的詞可能是系統自動加入,或是透過與使用者的互動所產生,前者可稱為「檢索詞擴展」(query
expansion)[29],後者可稱為「相關詞提示」(term
suggestion)[30]。另一種提昇檢索成效的方式是「相關回饋」(relevance
feedback)[31],亦即就目前找到的文件中,挑取重要的特徵,回饋給系統,以期找到更多的相關資料。此種特徵若是文件本身,則可稱為相關文件回饋(document
relevance feedback),若為相關詞,則稱為相關詞回饋(term
relevance feedback)。若由檢索到的相關文獻的主題標目再去進行檢索,則是專業資訊人員檢索時常用的檢索策略,也可說是相關回饋的一種方式。相關回饋有以下的優點
[32-33]:一、讓使用者免於選擇檢索語彙與設計查詢條件的細節,允許建構有用的檢索條件而不用對檢索環境及資料庫有深入瞭解;二、把檢索的過程拆解成一步步較小的步驟,可以逐漸逼近所要檢索的主題;三、提供一個控制的查詢修改過程,終端使用者僅需最少的訓練就可有效而合理的進行檢索。水晶檢索系統裡的「相關詞提示」功能,是從35萬多筆書目記錄的題名(即書名)中,自動擷取出11萬多條詞而建成的詞庫。此詞庫可供使用者作近似字串的查詢,以獲得資料庫中實際使用的詞彙及其出現的頻率,從這些系統提示的詞彙中使用者可選擇較為恰當者進行資料庫的查詢。至於系統裡的「相關詞回饋」功能,則是從檢索結果的每頁20筆資料當中,立即擷取出與檢索詞彙共同出現(co-occurrence)的相關詞,並依詞頻及詞彙的廣義與狹義關係排序,以提示相關於檢索主題的詞彙,讓使用者逐漸逼近自己所要找的主題資料。水晶檢索系統的檢索模式雖然主要為向量模式,但在「相關詞提示」及「相關詞回饋」的功能上作了一些變動,使系統的表現較符合使用者的期望。此點將透過下面的範例加以說明。
二、檢索範例
水晶檢索系統除運用在書目檢索上,也運用在新聞全文資料庫上。由於本文針對書目系統討論,運用在新聞全文資料庫上的情形,將僅作必要的補充說明。底下就此系統整合在現有OPAC系統,略舉範例對其功能作進一步的說明。
輔仁大學圖書館目前使用的系統架構在網際網路上,可提供讀者時、空無礙的檢索服務。在此檢索系統裡,整合了水晶檢索系統與廠商的檢索系統(網址:http://xlib.fju.edu.tw/,如附錄一)。廠商的檢索系統提供較為完整的檢索項目,可從各個檢索點查詢書目記錄。我們開發的檢索功能則提供題名與作者欄位的「模糊搜尋」(即「近似字串比對」)、以及「相關詞提示」的功能。查詢結果按相關程度排序,使用者可從「相關詞回饋」的功能,再作進一步的查詢。
根據國內外對OPAC系統的使用研究,最常被使用的檢索點為書名、作者、標題、與關鍵字。以83年邱韻玲對清大
OPAC使用情形的調查為例
[34],在3663次的檢索中,利用關鍵字查詢的比例佔40.4%,書名34
%,作者13%,標題2.9%。其中關鍵字、書名、作者三個檢索點的查詢比例合計達87%。而關鍵字是指出現在書名、作者、譯名或其他欄位中較具意義而關鍵的字或詞,至於實際涵蓋哪些欄位則各個圖書館或各家廠商的作法並不一致。另外,85年李宜容對中央研究院圖書館的人文及社會科學讀者使用OPAC的調查顯示
[35],在592次的檢索中,利用書名查詢的比例佔34%,作者26.9%,關鍵字20.8%,標題18%,其中書名、作者、關鍵字三個檢索點的查詢比例合計達81.7%。顯然,在實際的檢索中,書名、作者是使用者最常用以找尋書目資料的依據。由於我們主要目的在開發具有實用與研究價值的檢索技術,以提供使用者更便利有效的資訊檢索服務,而不是開發替代性的產品,因此我們僅就最常被使用的檢索款目開發檢索功能。目前使用者可從單一欄位中,輸入書名、作者、甚至與這些項目近似的任何字串,以查詢資料。因此,此系統可視為具備書名、作者、與關鍵字三個檢索點的書目檢索系統。
如前所述,「相關詞提示」可以協助使用者選擇較精確的檢索詞彙。例如,使用者若想找社會學有關的資料,輸入「社會學」直接查詢書目資料庫,將找到496筆完全符合的書目記錄,瀏覽這496筆資料以找尋真正需要的資料需要耗費相當的工夫。此例中,使用者可以先查詢「相關詞提示」,如圖一,系統將回應與「社會學」字串相近的相關詞,如「教育社會學 」、「現代社會學 」、「政治社會學 」、「兩性社會學 」等較為特定的詞彙。這些詞彙是依據符合程度以及出現的頻率排序顯示,因此使用者可從這些系統提示的相關詞中,迅速瞭解館藏資料分佈的情形,據以選擇適當的詞彙檢索資料庫,以快速獲得想找的資料。從此例中也可看出「相關詞提示」有一個額外的功能,亦即當輸入的檢索詞彙包含較廣的主題範圍時,系統提示的詞彙猶如一個動態分類表,較特定或專指性(specific)主題的相關詞會顯示出來供使用者瀏覽。此情形也發生在「心理學」、 「化學」、 「數學」等這些館藏較齊全的主題資料上。雖然此功能的效果可能不如人工製作的分類表,但仍可作為一個隨資料庫成長的輔助性動態分類目錄。
圖一:相關詞提示範例一

圖二:相關詞提示範例二
除此之外,由於本系統採用模糊搜尋技術加強檢索能力,查詢時先搜尋相關詞庫,也可以排除不必要詞彙的干擾。例如以「國科會」為檢索詞查詢「相關詞提示」,系統回應27筆與國科會近似的檢索詞,如圖二(因版面有限,此圖中間自「中國科技史」至「美國科學家小傳」部份被省略掉)。其中第一筆「國科會」正是我們要的檢索詞,其比對程度為1000分,即完全比對正確。最後一筆「國家科學委員會」與原檢索詞意思完全一樣,其比對的程度較低,僅375分。這兩個詞彙中間有數個詞比對程度為562,比「國家科學委員會」高。換言之,若使用者以「國科會」一詞直接檢索書目資料庫,則排列在最前面的資料為包含「國科會」符合需求的結果,但其後有好幾筆不符合需求的資料出現,其後才又出現包含「國家科學委員會」符合需求的資料。這種情況可能會讓使用者在循序瀏覽結果時一看到不相關的資料後,就放棄後續的瀏覽動作,而遺漏了更後面的相關的資料。因此,模糊搜尋此一檢索模式雖然允許找到更多相關資料,有較高的查全率,但同時也有可能引進過多的不相關資料,而傷害到查準率。解決的辦法是先查詢「相關詞提示」,從中過濾掉不相關的詞彙而僅選擇必要的檢索詞,在此例中即僅選擇「國科會」、「國家科學委員會」兩詞,再進行書目資料的檢索,如此可以降低模糊搜尋的負面效應。但此時檢索詞已確定,如果檢索模式還是使用模糊搜尋(向量模式),其效果就如圖三所示。「國科會」與整個查詢字串的符合程度並不高,若以圖三的檢索字串直接查詢書目資料庫,在檢索結果中仍舊會有其他近似程度相同的不相關文件(如「全國委員會」)與包含「國科會」的文件交互出現。所以在檢索詞確定後,檢索模式就要從模糊搜尋(向量模式)轉換成前後切截的精確比對模式,以避免檢索到非相關的資料,並符合使用者對檢索結果的預測。不過由於系統是以N-gram而非以詞庫的方式來建構索引詞,因此字串的精確比對(尤其是長字串以及同時多個字串的比對)仍然由向量檢索模式模擬,此時對每個檢索詞僅需輸出相似度最大的文件,若檢索詞有兩個或兩個以上,則將文件以含檢索詞個數的多寡由多至寡排列。圖四顯示的就是利用此種比對方式達到的檢索結果。

圖三:模糊搜尋的比對結果

圖四:修飾過的比對模式檢索結果
在前面的例子中,讀者可以發現系統提示的相關詞當中有不合法的詞彙出現(如圖二中的「國科」一詞)。此乃關鍵詞自動擷取模組不瞭解真正的語意之故,它只是一個根據規則運作的演算法,因此會有擷取錯誤產生不合法詞彙的情形。此演算法從356,000筆書目資料中擷取出11,840條詞,取其中樣本8,982條詞,經18位大三大四同學判斷得合法詞8,123條,不合法詞859條,正確率為90.4%。另外從13,035篇新聞全文文件中擷取出66,500條詞,經7位研究生判斷得合法詞57,389條,不合法詞9,111條,擷取正確率為86.3%。由於出現不合法詞彙的比例不高,我們就沒有投入額外的人力過濾這些詞彙,但我們在後面的線上問卷調查中就此情況詢問使用者的反應,此調查結果將做為我們是否進一步過濾這些不合法詞彙的參考。

圖五:相關詞回饋範例(中文詞彙)
此系統回應的檢索結果,不僅按相關程度排序,便利結果的檢視,而且也從每一頁的結果當中擷取出相關詞來,提供使用者進一步檢索的參考。與「相關詞提示」不同的地方,在於以此種方式呈現出來的相關詞,不僅限於相近的字串,一些與檢索主題常常一起出現的相關詞彙也會出現。例如,檢索「素食」,那麼回應的結果中有「健康」、「長壽」等字面上不相近但主題相近的詞彙,如圖五。圖六顯示的範例是以「image
processing」一詞尋找資料,在相關詞回饋中出現「computer
vision」的情況。因此「相關詞回饋」的功能,有拓展使用者檢索詞彙、導引檢索方向的作用。同樣的,為了較符合使用者對結果的預測,「相關詞回饋」的檢索模式也同「相關詞提示」一樣作了相同的變動。此一變動多少會影響資料的查全率,因應之道就是選擇多一點的相關詞彙一起檢索,以期涵蓋最多的相關資料。
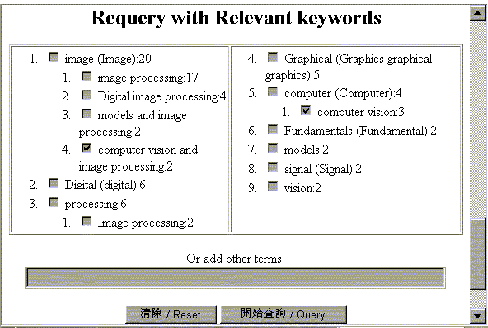
圖六:相關詞回饋範例(英文詞彙)
有關圖書館OPAC
檢索系統的研究方法,一般有以下幾種:(1)問卷法(2)比較研究法(3)檢索記錄檔分析法(4)面談法(5)實驗控制法。問卷法通常用來瞭解反應、接受度。比較研究法通常用在比較OPAC系統的特色。檢索記錄檔分析法則可讓評估者由各個觀點看到與系統績效有關的各種描述。面談法適用於瞭解使用者對系統的意見或比較不同系統的特性。實驗控制法則以實驗組和控制組的方式測試系統的成效,以設計較佳的使用者介面,或作為使用者檢索特性分析的測試
[36-38]。
至於在OPAC檢索系統的評估方法上,由於OPAC也是資訊檢索機制的一種,因此在檢索成效的評估上,則多採自資訊檢索領域的相關研究,諸如以檢索出的文獻的相關或是效用來評估檢索系統的良莠
[39]。此外,由於OPAC目的在提供符合使用者資訊需求的檢索服務,讓使用者能夠找到滿意的資料,因此有關OPAC的檢索成效,也可由讀者的觀點─「滿意度」(Satisfaction)來對線上公用目錄與讀者的互動間做更整體性的評估
[40]。
綜合過去的研究方法,本文將採取線上問卷調查法、檢索記錄檔分析法以及資訊檢索領域常用的查全率、查準率來衡量使用者的反應以及檢索的成效。
就第一項研究目標,我們將採線上問卷調查配合檢索記錄檔分析法來瞭解檢索系統使用的狀況。過去我們曾針對「模糊搜尋」的功能作了檢索記錄。使用者每次的檢索,其檢索條件、系統回應的筆數、檢索結果最高的符合程度、系統反應時間、使用者電腦的網路位址,以及查詢的日期與時間,都被系統自動記錄在日誌檔裡。經分析1997年9月至1997年12月共4個月約10613筆日誌檔記錄,系統平均每次檢索時間(包含檢索詞處理、索引檔讀取、相似度計算、從檔案讀取檢索結果、及從結果中動態擷取出相關詞作為「相關詞回饋」的動作)為
2.6秒(Pentium
II等級的200
MHz CPU),其中
61% 的檢索可在
1 秒內完成,79%
的檢索可在
2 秒內完成,87%
的檢索可在3
秒內完成。另外,使用者約從1832台不同的電腦連線過來查詢,亦即平均每台電腦連線過來做了5.8
次檢索。有5597次(52.7%)的查詢,有找到完全符合檢索字串的情形(即符合的程度為
1000),而有399次(3.8%)的查詢,有完全找不到符合檢索字串的情形(即符合的程度為0)。在使用者的查詢字串方面,中文檢索詞平均為5.2個中文字,有1591次(15%)的查詢為2
個字的中文詞,1366次(12.8%)的查詢為3個字的中文詞,1408次(13.3%)的查詢為4個字的中文詞。而英文檢索詞平均為15個字母的英文字或詞。
上述的資料顯示,檢索記錄檔可以提供相當豐富的資料,作為系統設計的參考。本研究將改進檢索記錄檔的格式,記錄更多的訊息,如使用者查詢時的檢索欄位、檢索畫面、以及使用的檢索功能等,並針對參與填答線上問卷的檢索記錄作分析,以瞭解各個檢索功能被利用的情形,達到第一項研究目標。
在第二項研究目標方面,資訊檢索領域裡經常利用的「查全率」(recall
rate或稱「召回率」)、「查準率」(precision
rate或稱「精確率」)作為評估成效的指標。然而在求查全率、查準率時,必須針對每一次的查詢,找出資料庫中所有相關資料的筆數,並且針對查詢結果的每一筆資料,進行相關性的判斷。輔大的書目資料至少有35萬筆,核對35萬筆資料的相關性是相當龐大的工作。在資訊檢索領域中,通常有專門作為評估用途的資料庫,如TREC
[41],可做查全率、查準率的評估。此種資料庫有專門的研究機構準備好各種檢索範例,以及列舉出與每一個檢索範例相關的所有記錄。由於「查全率」、「查準率」表現的數據,通常是在相同的條件下,比較不同的檢索方式或檢索功能,才顯得出其意義。在國內缺乏這種測試資料庫的情況下,勢必要採取其他的方式來評估檢索成效。
由於新的檢索功能,能允許使用者輸入傳統布林邏輯無法表達的查詢條件,所以這兩種檢索系統之間無法直接比較。但同樣屬於新功能的「模糊搜尋」、「相關詞提示」、「相關詞回饋」則有相同的比較基礎,我們不必一一核對35萬筆資料的相關性,即可求得相對的查全率、查準率。因此,第二項目標:新功能所能達到的效果如何,可由此兩項指標提供理想狀況下的參考數據。
如前所述,新的檢索功能,對於那些檢索條件不能精確表達、或檢索需求以傳統方式不易表達的查詢,可以達到相當程度的檢索效果。此種情況,在實際的檢索環境中是否經常發生,發生的比例多少?在第一項目標中,透過檢索記錄檔的觀察,並不能回答此問題。我們必須進一步瞭解使用者想找什麼資料,如何表達其檢索條件,表達檢索條件時利用新的功能的情形,是否因此而找到資料等等。因此,我們將以線上問卷調查的方式,來瞭解第二項目標,即新的功能在實際的檢索狀況中,能夠發揮效果的情況如何。
至於第三項目標,瞭解使用者對檢索功能與檢索結果的看法方面,我們同樣採用線上問卷法,讓使用者在線上檢索完後,立即填答問卷。如此可以排除時、空的障礙,長期而持續的蒐集使用者的問卷填答結果。
利用檢索記錄檔蒐集各個檢索點的使用情況時,需要設計介面程式介於使用者與檢索引擎之間,以取得使用者的檢索條件,以及檢索引擎的回應結果。輔大圖書館的書目檢索系統裡,整合了我們自己以及廠商開發的檢索系統。此兩種檢索系統分別安裝在兩部主機上,且輸出格式不一致,造成介面程式必須透過網路,即時抓取檢索系統的回應結果,並即時送回格式一致的檢索結果給使用者的困難。所幸透過全球資訊網路的超文件傳輸協定(HyperText
Transfer Protocol, HTTP),我們克服了此種難題,完成此項介面程式的設計與測試,並將線上問卷整合在檢索系統中。
線上問卷雖然可以解決時、空的障礙,持續的蒐集問卷,但使用者會不會主動填答問卷,則難以掌握。況且我們在作此調查時,學校的系統尚未驗收完成,還沒正式啟用,最後也有可能發生回收問卷數量不足的情況。以我們的線上問卷測試版為例,放上網路將近一星期的時間,書目資料總共被檢索1212次,但使用者自發性填答問卷測試版的則只有5位。有鑑於此,我們在正式的問卷上線時,透過下列措施改善問卷填答不踴躍的情況:一、將問卷調查以最醒目的方式呈現在檢索主網頁上;二、到各大電子佈告欄(BBS)上張貼公告,邀請網友填答線上問卷;三、以信函寄交全校各班班代,委請宣佈該問卷事宜及網址,廣邀全班同學參與。
本研究所採用的線上問卷(詳如附錄),主要分為兩部份:(一)檢索前問卷:旨在瞭解填答者的基本資料與此次檢索的特性,如附錄二;(二)檢索後問卷:旨在瞭解使用者對此次檢索的看法,如附錄三。使用者利用瀏覽器連上檢索主機後,可選擇直接進入檢索主畫面,或選擇參與填答線上問卷。若使用者選擇填答問卷,系統則回應檢索前問卷供使用者填答。填答完畢則進入檢索主畫面,此時使用者可自由選擇「欄位式查詢」(即傳統的查詢模式)或「近似字串查詢」(即我們發展的系統)進行資料查詢。系統在每頁查詢結果中都有一個按鍵提示使用者可隨時結束查詢進入檢索後問卷。填答完此問卷後即完成整個問卷流程。此問卷系統於1998年4月28日正式上線進行資料收集,於5月19日截止。在此期間,總共有1647位使用者連線查詢,其中有1371位選擇不回答問卷,有156位填答了檢索前問卷,但資料查詢完後沒有接續填答檢索後問卷。最後填答完整者有120筆,扣掉重複與填答明顯前後不一致的情況4筆,留下116筆可用的調查結果(填答率約7
%),總共297次的檢索記錄
[42]。
一、受訪者特性分析
(一)受訪者身份
此次調查蒐集到的116位受訪者資料,以大學生的70名(60%)最多,其次是碩士班學生28名(24%),博士班學生有3名(2.6%),大學老師、研究人員、研究助理、圖書館員各1名(0.9%)。此外,由於此次問卷調查架構在WWW上,因此也有11名社會人士受訪,佔9.4%的比例。
(二)學科背景
受訪者學科背景,以文科居多,佔全體的41.3%(48位),其次是理科16.4%(19位),商科12%(14位),再其次是法科、工科背景,分別為8.6%(10位)、7.8%(9位),而比例最少的是農科與醫科的0.8%(1位)與1.7%(2位)。整體而言,文、理、商學科背景的受訪者較多,合計比例為61.9%,其他學科背景較少,加起來只有38.1%。
(三)找尋資料的目的
受訪者找尋資料的目的,有65人(55.2%)為寫報告所需而使用書目檢索系統,佔一半以上比例;其次是為興趣找尋資料有17人(14.7%);再其次是為進行論文或研究的文獻蒐集有12人(10.3%);接著才是為找尋論文或研究題目所需、為考試所需、為教學所需,比例都在10%以下;在其他項目中,則有增加專業需求、為做讀者服務、查詢圖書館是否有書、以及自修和受人之託代為查詢等其他目的。
(四)檢索系統的使用經驗
若將本研究受訪者使用檢索系統的經驗,依熟悉程度分為「非常熟悉」、「熟悉」、「有點不熟悉」和「非常不熟悉」四個等級。在近似字串檢索系統方面,如表1所示:計有59.5%的受訪者對近似字串檢索系統感到「非常熟悉」或「熟悉」,而表示「有點不熟悉」的有34.5%,只有6%的人表示對近似字串檢索系統感到非常不熟悉。若依熟悉程度由高到低編碼為4、3、2、1四個數字,則116位受訪者的平均熟悉程度為2.7,標準差為0.77。而在欄位式檢索系統方面,表示「非常熟悉」或「熟悉」的人佔全體的52.6%,表示「有點不熟悉」的比例為26.1%,表示「非常不熟悉」的比例佔20.7%。以同樣的編碼方式求其平均熟悉程度為2.4,標準差為0.95。
|
檢索系統 | ||||||
檢索 | ||||||
檢索 | ||||||
綜合受訪者對兩種檢索系統的熟悉程度,以對近似字串檢索系統的熟悉程度稍高,且在不熟悉程度上兩者差異較大。若將「非常熟悉」、「熟悉」合併成「熟悉」,「有點不熟悉」與「非常不熟悉」合併成「不熟悉」,經由卡方考驗,在α=.05的情況下,計算所得卡方值為1.12,較查表所得3.841(df=(2-1)(2-1)=1)為小,因此未達顯著差異,顯示使用者對兩種檢索系統粗略的熟悉程度上差別並不大。
至於受訪者為何對各種書目檢索系統當中較少見到的「近似字串檢索」並不陌生,可能是因為越來越多的網頁全文檢索系統提供類似的服務,也有可能是「近似字串檢索」的功能在此次問卷調查之前已出現了一個多學期,對大部份為輔大學生的受訪者而言已不陌生。
(五)受訪者選擇使用的檢索系統
如前所述,受訪者進入系統後,可自由選擇「近似字串檢索」或「欄位式檢索」系統進行查詢。在116位受訪者中,有85位選擇「近似字串檢索」系統,31位選擇「欄位式檢索」系統。受訪者對檢索系統的熟悉程度與其選用的檢索系統之間是否有關連可由表2運用統計方法求得。為方便討論,同樣將「非常熟悉」、「熟悉」合併成「熟悉」,「有點不熟悉」與「非常不熟悉」合併成「不熟悉」,那麼對「近似字串檢索」系統而言,經獨立性卡方考驗
[43],求得卡方值為0.378,較查表值3.841為小,亦即,受訪者選用「近似字串檢索」系統與對此系統是否熟悉並無關連。對「欄位式檢索」系統而言,同理可求得其卡方值為7.9,比查表值3.841大,因此,熟悉「欄位式檢索」系統與選用此系統之間有所關連,其相關係數為SQRT(7.9/116)
= 0.26,亦即對「欄位式檢索」系統熟悉者,會傾向選用「欄位式檢索」系統。
| 檢索系統 |
| |||||
檢索 | ||||||
檢索 | ||||||
另一個有趣的觀察,是從機率理論來推導受訪者對系統的熟悉程度是否與選用該系統相關。例如,令P(Xa)表示對a系統熟悉的機率,並令P(Ya)表示選用a系統的機率,則P(Ya|Xa)為對a系統熟悉的情況下選用a系統查詢的機率。若熟悉的系統與選用的系統無關時,那們根據機率原理,P(Ya|Xa)
= P(Ya且Xa)/P(Xa)
= P(Ya)P(Xa)/P(Xa) = P(Ya)。對「近似字串檢索」系統而言,P(Ya)=
85/116 = 0.73,而P(Ya|Xa)
= (10+42)/(14+55) = 0.75,兩者值非常接近,即P(Ya)
近似
P(Ya|Xa),說明熟悉「近似字串檢索」系統與選用該系統之間並無關連。對「欄位式檢索」系統而言,同理可求得其P(Ya)
= 31/116 = 0.27,P(Ya|Xa)
= (6+17)/(14+47) = 0.38,兩者值差異較大,顯示熟悉該系統與選用該系統之間並非互為獨立事件。
(六)能否精確表達檢索條件與選用的檢索系統交叉分析
前面曾經討論過,近似字串檢索系統適合檢索條件不能精確表達,或檢索需求以傳統方式不易表達的查詢。因此,我們特別請受訪者描述其所想找尋的資料,將其檢索條件分為「可以精確描述」與「不能精確描述」兩類。前者係指使用者在進行檢索時能夠輸入正確的書名、作者名、ISBN、叢書名或出版項等已知書目所表達的檢索條件;後者是指使用者針對某一主題進行檢索,或者是針對想找的資料無法詳記其書名、作者名等書目資料所下的檢索條件。如表3所示,有37人(31.9%)顯示能夠精確表達其檢索條件,有79人(68.1%)顯示不能。若就此因素與受訪者實際選用檢索系統的情況分析其關連性,利用表3的資料及前述的獨立性卡方考驗,發現計算所得卡方值為10.25,比查表值3.841大。顯示此次的受訪對象,大多無法精確表達其檢索條件,且在此情形下大部份選擇近似字串檢索系統進行資料查詢。
二、檢索點的使用分析
檢索點是資料庫中可供檢索的欄位或款目,如書名、作者等。雖然近似字串檢索系統裡目前只能就書名與作者資料進行查詢,我們仍將其提供的三種功能,即「模糊搜尋」、「相關詞提示」與「相關詞回饋」視為檢索點,以便和欄位式檢索系統一起討論,描述受訪者檢索時的行為。
(一)檢索次數分佈
在116位受訪者,共297次的檢索中,平均每人進行了2.56次的檢索。檢索次數以2次的48人(41.4%)最多;其次只檢索1次的比例也很高,有35人(30.2%);再其次,是進行3次檢索的比例,有17人(14.4%)。其餘檢索4次及5次者皆有4人(3.5%),6至8次者各有1人(0.9%),9次2人(1.7%),10至13次及15次者各1人。總計進行1-3次檢索的百分比為86%。
(二)檢索點的使用次數
使用「近似字串檢索」系統的次數有236次,佔全部檢索次數的79.5%;使用「欄位式檢索」系統的次數有61次,佔20.5%。至於個別檢索點的使用次數,如表4所示:以模糊搜尋的134次(45.1%)為最高,其次是相關詞提示79次(26.6%),再其次為題名,有30次檢索(10.1%)。其餘的檢索點被使用的比例則低於10%,分別是相關詞回饋的7.7%、作者4.7%、關鍵字3.7%、標題0.6%。多欄交集查詢的比例也十分低,只有3次的檢索使用題名和作者兩個檢索點同時查詢,佔全部比例的1%而已。另外有一次的檢索,首次檢索時使用欄位式檢索系統,但並未在任何檢索點輸入任何檢索詞彙就進行查詢,其後又轉向近似字串檢索系統使用相關詞提示功能,對於此次空白的檢索,研究者以「空白」在表格中表示,以利統計。
檢索 | 134 | 45.1% | |
| 79 | 26.6% | ||
| 23 | 7.7% | ||
檢索 |
30 | 10.1% | |
| 14 | 4.7% | ||
| 11 | 3.7% | ||
| 2 | 0.6% | ||
| 3 | 1.0% | ||
| 1 | 0.3% | ||
| 297 | 100.0% |
(三)檢索點的使用變化
大部份資料查詢的過程,是一次次的嘗試以找到更齊全的資料或漸漸逼近自己要找的資料。透過檢索點使用變化的分析,可以瞭解各個檢索點在不同階段扮演的角色。
1、首次到第二次檢索的使用變化
在全部116人次的檢索中,扣除僅進行一次檢索的35人次,共有81人次進行了兩次以上的檢索。表5顯示:
| Ⅱ
Ⅰ | 搜尋 | 加作者 | ||||||
2、第二次到第三次檢索的使用變化
有48位受訪者僅檢索2次,進行三次以上檢索的人剩33位,如表6所示:
(1)由模糊搜尋出發的比例最高,這當然與首次到第二次檢索時,大多數由相關詞提示轉向模糊搜尋有關。在17人次中,有9人次(27.3%)仍繼續使用模糊搜尋,其次是改用相關詞回饋,有6人次(18.2%)。
(2)由相關詞提示出發的檢索,其比例由首次到第二次的69.1%驟降到27.3%。在總共9人次中,轉向模糊搜尋的比例,有6人次(18.2%),持續使用相關詞提示的僅3人次(9.1%)。
(3)由題名出發的檢索計3人次,僅佔9.1%。其中2人停留在題名繼續查詢,有1人轉向關鍵字。
| Ⅲ Ⅱ | 提示 | 搜尋 | 回饋 | |||
3、第三次到第四次檢索的使用變化
進行三次以上查詢的剩16人,表7顯示第三次到第四次的使用變化:
(1)由相關詞提示出發的檢索有5人次,佔31.3%。其中的4人在第四次檢索轉用模糊搜尋,1人仍繼續使用相關詞提示。
(2)由模糊搜尋出發的有4人次佔25%。其中有3人在第四次檢索仍繼續使用模糊搜尋,有1人轉用相關詞提示。
(3)由相關詞回饋出發的有3人,比例由原先的6.1%上升到18.8%。其中2人在第四次繼續使用相關詞回饋,另有1人轉用欄位式檢索系統的題名。
(4)由題名出發的檢索有4次,比例由原先的9.1%上升到25%。其中2次在第四次檢索時仍持續使用題名,有1人轉用作者,另1人轉用近似字串檢索系統的相關詞提示。
| Ⅳ Ⅲ | 提示 | 搜尋 | 回饋 | |||
綜合而言,在近似字串檢索方面,大部份受訪者首次檢索採用相關詞提示,繼而採用模糊搜尋,之後繼續採用模糊搜尋或相關詞回饋。而且由表8的交叉分析資料及前述的獨立性卡方考驗及機率理論分析,在前三次的檢索當中,受訪者選用某一檢索功能與受訪者對系統的熟悉程度並無關連。在欄位式檢索系統方面,接近六成的使用者僅進行一次檢索即離開系統,31人中僅13人(41.9%)進行一次以上的檢索,而且從上面三個表中看出,受訪者在連續三次的檢索點變化中,都是以題名到題名的使用比率較高。
| 檢索系統 |
| |||||
檢索 | ||||||
檢索 | ||||||
檢索 | ||||||
註:在第二次及第三次檢索中,大部份受訪者均是在使用相關詞提示之後
再利用模糊搜尋,其前一次不使用相關詞提示而在這一次就直接以模糊搜尋
重新查詢資料庫者,說明如下:*
29人中僅3位直接以模糊搜尋重新查詢;**
19人中有2位;***
5人中有1位。
三、受訪者對檢索結果的看法
(一)自動排序
自動排序功能對使用者瀏覽檢索結果是否有幫助,由表9可見:覺得非常有幫助的比例為27.1%、有幫助的比例為55.3%,只有1.2%的人認為沒有幫助,8.2%的人認為不太有幫助。因此整體而言大部份人(82.4%)覺得自動排序功能對瀏覽檢索結果有所助益。此外,未曾注意到此功能的人僅佔3.5%,意味著96.5%的人都注意到了這個功能,而不瞭解此功能作用的比例也很低,只有4.7%。
| 有幫助 | 57.7% | 47.1% | ||||
| 非常有幫助 | 12.9% | 21.2% | ||||
| 不太有幫助 | 10.6% | 11.8% | ||||
| 未曾注意到此功能 | 9.4% | 9.4% | ||||
| 不瞭解此功能的作用 | 4.7% | 3.5% | ||||
| 沒有幫助 | 2.4% | 3.5% | ||||
| 知道此項功能但未使用 | 2.4% | 3.5% | ||||
| 100% | 100% | |||||
(二)相關詞提示
相關詞提示對受訪者選擇檢索詞彙是否有幫助,由表9可見:覺得非常有幫助的比例為12.9%、有幫助的比例為57.7%,兩者合計為70.6%。相對的,有10.6%的人認為不太有幫助,有2.4%的人認為沒有幫助。至於未曾注意到此功能的佔9.4%,表示有九成以上的人都注意到了這個功能。而不瞭解此功能作用的比例為4.7%,知道此項功能,但未曾使用的比例為2.4%。
(三)相關詞回饋
相關詞回饋是否能幫助受訪者進一步發現相關資料,由表9可見:認為有幫助的佔47.1%,認為非常有幫助的佔11.8%,兩者合計為58.9%。另外,有21.2%的人認為不太有幫助,有3.5%的人認為沒有幫助。不瞭解此項功能作用的只佔3.5%。另有9.4%的人未曾注意到此功能,可能是相關詞回饋被設計在檢索結果畫面的最下端,有些人沒有發現。此外,也有3.5%的人知道此項功能,但對是否有幫助未置可否,而填答未曾使用。
(四)不合理詞彙
此外,在相關詞提示與相關詞回饋中偶會有不合理詞彙出現,受訪者對此種現象的接受程度如何?表10顯示:認為不合理詞彙比例不多可以接受的有43.5%;其次是覺得沒關係可以接受的為22.4%;有14.1%的人未曾注意到有不合理詞彙,以上三者共計有80.0%的比例,即八成的受訪者偏向不在乎有否不合理詞彙的出現。但也有18.9%的人認為不合理詞彙的比例太多不能接受;有1人認為完全不能接受不合理詞彙,比例是1.2%。
| 不合理詞彙比例不多,可以接受 | 43.5% | |
| 沒關係,可以接受 | 22.4% | |
| 未曾注意到有不合理詞彙 | 14.1% | |
| 不合理詞彙比例太多,不能接受 | 18.9% | |
| 完全不能接受,希望不要有這種情形 | 1.2% | |
| 100% |
(五)檢索結果滿意程度
受訪者對近似字串檢索系統的檢索結果滿意程度,如表11所示:有13人(15.3%)表示非常滿意,41人(48.2%)表示滿意,二者合計為63.5%,顯示使用近似字串檢索系統的受訪者,有六成以上滿意其檢索結果。不過也有29人(34.1%)表示不太滿意,有2人(2.4%)表示不滿意。若依滿意程度由高到低編碼為4、3、2、1四個數字,則85位受訪者的平均滿意程度為2.8,標準差為0.73。
| ||||||
| ||||||
欄位式檢索系統的受訪者對檢索結果感到非常滿意的有2人(6.5%),感到滿意的有17人(54.8%),二者合計為60.7%,顯示也有六成的受訪者對檢索結果表示滿意。此外有10人(32.3%)表示不太滿意,有2人(6.4%)表示不滿意。以同樣的編碼方式求得31位受訪者平均滿意程度為2.6,標準差為0.7。
若將此滿意程度作卡方考驗,在α=.05的情況下,計算所得卡方值為2.7,較查表所得7.815(df=(4-1)(2-1)=3)為小,因此未達顯著差異,顯示不同受訪者族群對兩種檢索系統的檢索結果在四種滿意程度上差別均不大。
若將「檢索結果滿意度」與「能否精確表達檢索條件」作交叉表列,如表11所示,再以卡方考驗分析:就近似字串檢索系統而言,使用者能否精確表達檢索條件,在檢索結果滿意度方面並無顯著差別。此情況對欄位式檢索系統亦同。若就「無法精確表達查詢條件」分析,兩種系統在受訪者對結果的滿意度上表現相當。若就「可以精確表達查詢條件」分析,兩種系統的表現同樣也無顯著差別。
原先預估「近似字串檢索」系統對檢索條件無法精確表達的查詢應能提供較佳的滿意度,然而上述結果與預期不同。經研究者透過檢索記錄檔實際瞭解這些無法精確表達檢索條件的檢索過程,發現這些使用者雖然不能用作者名或精確的書名表達檢索條件,但在使用後切截題名檢索或是前後切截的關鍵字比對後就可以找到所要的資料。此種情形即無法凸顯近似字串檢索系統比對資料的能力。
(六)找到資料的情形
除了上述有關滿意度的四點尺度調查外,詢問受訪者找到資料的情形,亦可深入瞭解受訪者獲得檢索結果的真實情況,反映出使用者與系統間的互動結果。
近似字串檢索系統的受訪者找到資料的情形,由表12可見:表示「是的,正是我所要的資料」的人有30位(35.3%);有27位(31.8%)認為找到資料的情形是「是的,但仍有限」;有14位(16.5%)表示「部份有我要的資料」;有5位(5.9%)認為「是的,並非原本我要找的,但發現了其他有用的資訊」。因此總計有89.5%的比例,近九成的人表示找到資料。而回答「完全沒有找到」的比例僅有7.1%而已。另有3.5%選擇其他,如:認為找到的資料太多、有找到資料但借不到。
| 檢索系統
找到資料的情形 | ||||||
| 1、是的,正是我要的資料 | ||||||
| 2、是的,但仍有限 | ||||||
| 3、部份有我要的資料 | ||||||
| 4、是的,並非原本我要找的,但發現了其他有用的資訊 | ||||||
| 5、完全沒有找到 | ||||||
| 6、其他 | ||||||
使用欄位式檢索系統的受訪者找到資料的情形,由表12可瞭解:找到「是的,正是我要的資料」的比例是32.3%;找到「是的,但仍有限」的比例是35.5%;找到「部份有我要的資料」的比例有12.9%;找到「是的,並非原本我要找的,但發現了其他有用的資訊」的比例為3.2%。總計有83.9%的受訪者,有找到資料。此外,有16.1%的人表示「完全沒有找到資料」。
若將「找到資料的情形」與「能否精確表達檢索條件」作交叉表列,如表12所示,再以卡方考驗分析:就近似字串檢索系統而言,使用者能否精確表達檢索條件,在找到資料的情形方面並無顯著差別。此情況對欄位式檢索系統亦同。若就「無法精確表達查詢條件」分析兩種系統的差異,計算所得卡方值為11.46,比查表值11.07(df=(6-1)(2-1)=5)稍高,兩種系統的表現在統計上有其差別。其中近似字串檢索系統「完全沒有找到」資料的比例為6.2%,比欄位式檢索系統的14.3%較低,找到「正是我要的資料」的比例33.9%,比欄位式的14.3%高。這兩種情形是造成此兩系統差異較大的地方。
另外,在「可以精確表達查詢條件」的部份,雖然兩種系統在找到資料的情形上沒有統計上的顯著差別。不過使用近似字串檢索系統找到「是的,正是我要的資料」的比例有40%,但使用欄位式檢索系統的比例卻更高,有47.1%。這顯示如果使用者已經明確自己要找的資料,能夠正確的輸入書名或作者名,那麼欄位式檢索系統會是很好的選擇,因為它精確比對的模式,不會產生過多的資訊。但相對的,它「完全沒有找到」資料的比例也最高(17.6%),即失敗的情形最高,且找到「並非原本要的資料,但發現了其他有用的資訊」的比例是零,顯示它也不會提示其他額外的訊息。
(七)受訪者「找到資料情形」與「檢索結果滿意度」交叉分析
由表13的交叉分析可知:若求「找到資料情形」與「檢索結果滿意程度」間的積差相關係數,則r=.446,大於α=.01時的顯著性臨界值0.28(df=83),顯示受訪者找到資料的情形與檢索結果滿意程度有正相關的關係。對欄位式檢索系統而言,其r=.71,大於α=.01時的顯著性臨界值0.456(df=29),亦顯示受訪者找到資料的情形與檢索結果滿意程度之間也有正相關的關係。
| 檢索系統
檢索結果滿意程度
找到資料的情形
| ||||||||
| 1、是的,正是我要的資料 | ||||||||
| 2、是的,但仍有限 | ||||||||
| 3、部份有我要的資料 | ||||||||
| 4、是的,並非原本我要找的,但發現了其他有用的資訊 | ||||||||
| 5、完全沒有找到 | ||||||||
| 6、其他 | ||||||||
(八)受訪者檢索後「比原先預期找到資料的多少」與「檢索結果滿意度」交叉分析
由表14顯示,無論是使用哪一種系統的受訪者,檢索到的資料比原先預期的多寡,和檢索結果的滿意程度間的關係較不明顯。例如近似字串檢索系統中,找到資料「比原先預期的多」的人中,卻有6人對檢索結果感到「不太滿意」,另有9人雖然找到的資料「比原先預期的少」,但卻表示「滿意」或「非常滿意」,欄位式檢索系統也有類似的情況。不過,若求「比原先預期找到資料的多少」與「檢索結果滿意度」間的積差相關係數,在近似字串檢索系統部份則r=.4,大於α=.01時的顯著性臨界值0.28(df=83),顯示受訪者對近似字串檢索系統檢索結果滿意與否,與比原先預期找到資料量的多寡,仍有正向關係存在。但在欄位式檢索系統的部份,則r=.18,小於α=.01時的顯著性臨界值0.456(df=29),顯示受訪者對欄位式檢索系統檢索結果滿意與否,與比原先預期找到資料量的多寡並無太大關連。
| 檢索系統
檢索結果滿意程度
比原先預期找到資料情形
| ||||||||
| 比原先預期的多 | ||||||||
| 和原先預期的差不多 | ||||||||
| 比原先預期的少 | ||||||||
除了以問卷及檢索記錄瞭解此檢索系統實際的使用狀況外,我們也依據資訊檢索領域常用的指標:查全率與查準率,來衡量系統理想狀況下的成效。所謂查全率即系統找出相關資料的筆數與資料庫內所有相關資料筆數的比值。而查準率為系統找出相關資料的筆數與系統找出資料筆數的比值。查全率可鑑定系統找出所有相關資料的能力,而查準率可以鑑定系統過濾不必要資料的能力。在衡量系統檢索成效時,查全率與查準率是一起並用的,單獨檢視其中一個指標並無意義。例如,假設資料庫內有文件一萬篇,就某一個檢索主題,其中相關的文件有一百篇,若系統僅查詢出一筆資料,且此資料是相關的,則其查準率為100%,但此時系統漏掉了99篇相關文件。同理,若系統將資料庫裡所有的文件都當作查詢結果回覆使用者,則其查全率為100%,但此時系統查出9900篇不相關的資料。以查全率與查準率衡量系統成效時,可能的缺點在於判定文件與查詢主題的相關性,此種判斷是相當主觀的過程。雖然如此,配合一些降低主觀判斷的作法
[44],此兩指標仍是最被廣為採用的方法。
如前所述,新的檢索功能可允許布林邏輯無法表達的查詢條件,所以本實驗僅就「模糊搜尋」、「相關詞提示」、「相關詞回饋」三項功能作比較。亦即對「模糊搜尋」而言,是以檢索主題直接查詢資料庫,然後就此結果判斷其相關性。對「相關詞提示」而言,則先以檢索主題查詢相關詞詞庫,獲得系統提示的相關詞後,由測試者選擇較適當的詞彙再查詢資料庫,從而判斷檢索結果的相關性。對「相關詞回饋」而言,先以檢索主題直接查詢資料庫,獲得系統從檢索結果擷取的相關詞後,從中選擇適當者再查詢資料庫,以判斷檢索結果的相關性。如前面第二節所作的說明:直接以「模糊搜尋」查詢資料庫時的字串比對方式為N-gram向量模式,而從「相關詞提示」與「相關詞回饋」提示的詞彙中,選擇適當詞彙再間接查詢資料庫時的比對方式,則為修飾過的N-gram向量模式。此修飾主要在改變相似度的作法,使其具備精確比對的效果,並保留排序的功能。所以在這一節所提到的「相關詞提示」與「相關詞回饋」,實際上是對應到第四節檢索點變化中的「相關詞提示」再到「模糊搜尋」,以及「相關詞回饋」再到「模糊搜尋」的兩階段檢索。這第二階段的間接「模糊搜尋」其比對方式是修飾過的N-gram向量模式,與直接「模糊搜尋」的比對方式有所差異。
在相同的檢索條件、相同的資料庫下,我們將以直接「模糊搜尋」作為比較的基礎,求其他兩項功能與此功能的相對查全率、查準率,從而瞭解此三項功能相對的檢索效果。當然我們還可嘗試其他的檢索策略,例如先利用「相關詞提示」,從結果中選擇適當詞彙查資料庫,從此結果中再利用「相關詞回饋」的詞彙再查一次資料庫,最後就此結果才判斷其相關性。也就是從「相關詞提示」開始、再到間接「模糊搜尋」、再到「相關詞回饋」三種功能並用的情況。不過我們的目的在瞭解此三項功能的成效,而不是在組合各個功能以尋求最佳的檢索策略,因此就沒有往此一方向作進一步的評估。
除了利用書目資料庫作為測試資料庫外,我們也採用了前述的新聞全文資料庫以測試此檢索系統對全文文件的檢索效果。我們邀請了七位輔大圖資系的研究生,每個人對每一個測試資料庫出五道檢索主題,如「演進中的電影語言」、「宋楚瑜請辭風波對台灣政壇的影響」等。排除重複及相關文件數量太少的主題,每一個測試資料庫有30道檢索題目(詳細檢索題目,請參見[45])。
文件與檢索主題的相關性,就由這七位出題者就最前面的N筆結果自行判斷。在此我們N
選擇50,主要的考量是確保相關資料不致太少,並且亦不增加判斷者太多的負擔。表15為兩個資料庫各30個檢索主題的平均查準率與查全率。注意,由於資料庫中所有相關文件的筆數無法實際求得,我們即以此三項功能找到最多的相關筆數為計算的基準。所以實際的查全率並不清楚,但相對的查全率(即表15中的提昇比率)並不受此影響。
表15顯示「相關詞提示」在兩種資料庫上都有相當高的查準率,且在查全率上亦維持與「模糊搜尋」相同的水準,顯示在檢索詞確定、檢索詞彙數量足夠、並且與資料庫所使用的詞彙一致時,精確比對的效果較好。而「相關詞回饋」在書目資料庫上也有相當高的查準率,但查全率則下降6.6%;至於在新聞全文資料庫上,其查準率與查全率都比「模糊搜尋」高,但提昇的比率,沒有超過6.1%。「相關詞回饋」的查全率在不同的資料庫上有不同的表現,主要原因在於系統提示詞彙的個數多寡。由於書目資料庫每頁顯示20筆的檢索結果,從中能夠擷取的資訊僅20條題名,平均每頁擷取出的相關詞個數為9.2。相對的,新聞資料庫與一般的網頁查詢系統一樣,每頁顯示10筆資料,但因為是全文文件,能夠擷取的資訊較多,平均每頁可擷取出57條詞彙,因此其查準率與查全率都得以提昇。這意味著,如果「相關詞回饋」提示的詞彙,不限於每頁結果的局部資料,而是從更多頁、甚至整個資料庫擷取得來,也許能進一步提昇查準率與查全率。
| ||||
|
(+69.2%) |
(+2.4%) |
(+28.9%) |
(-1.1%) |
|
(+61.3%) |
(-6.6%) |
(+6.1%) |
(+5.0%) |
van
Rijsbergen曾提出一個將查準率與查全率兩數據結合成單一指標的方法
[46],即F
= 2PR/(P+R),其中P為查準率、R為查全率。若按此方法將表15的數據化成F指標的話,則在書目資料庫方面,相關詞提示比模糊搜尋的成效提昇38.2%,相關詞回饋則提昇29.1%;而在新聞全文資料庫方面,相關詞提示提昇18.2%,相關詞回饋則提昇7.3%。此結果顯示,查準率上的大幅提昇,補償了查全率上的輕微的損失,因此整體而言,相關詞提示與相關詞回饋的檢索效果比模糊搜尋為佳。
從以上的研究發現,新的檢索功能應用在線上公用目錄的成效結論如下:
一、多數受訪者會尋求近似字串檢索系統進行資料查詢,且此情形與受訪者對此系統的熟悉程度無關,但與受訪者無法精確表達查詢條件有關
調查顯示,大部份參與問卷調查的受訪者無法精確表達其檢索條件(比例為79/116=68.1%),而選用「近似字串檢索」系統者比例為73.3%。經獨立性卡方考驗驗證,受訪者選用「近似字串檢索」系統與是否熟悉此系統無關,但與無法精確表達查詢條件有正向關連。我們設計此系統的目的,即在提供一個能夠便利表達檢索條件的環境。此一結果顯示使用者的集體行為,符合我們設計此系統的目的。
二、多數受訪者能運用最有利的檢索過程進行資料查詢,且此現象與受訪者對系統的熟悉度無關
由檢索點使用的變化發現:首次到第二次檢索使用率最高的是相關詞提示到模糊搜尋,而相關詞回饋的使用率最多的是在第三次檢索。換言之,多數使用者會循著相關詞提示、繼而模糊搜尋、之後繼續採用模糊搜尋或相關詞回饋的步驟來進行檢索,這正符合此三項功能的設計意圖,顯示使用者能充分運用最有利的檢索過程來協助自己做資料的查詢。而且此種現象與受訪者對系統的熟悉程度並無關連,顯示系統的介面或流程設計不會阻礙受訪者對檢索系統作較佳的運用。
三、不論受訪者是否能夠精確表達查詢條件,近似字串檢索系統沒有比欄位式檢索系統提供較佳的檢索結果滿意度,惟在找到資料的情形上表現較佳
如第四節中所述,前後切截的關鍵詞比對即可滿足大部份「無法精確表達檢索條件」者的需求,既使近似字串檢索系統找到資料的情形較佳,但此情形還未讓受訪者感到較佳的滿意度。從檢索記錄檔的分析瞭解,我們覺得使用者大多僅以關鍵詞的概念去比對資料,雖然能將新的檢索功能作較佳的組合運用,但還未能真正瞭解並善用近似字串檢索系統的資料比對能力。
四、不合理詞彙多可接受
八成的受訪者對系統提示的詞彙,偶有不合理的情形(約10%)多可接受。此外,大部份受訪者也對「自動排序」、「相關詞提示」、「相關詞回饋」直接肯定其對瀏覽結果、選擇檢索詞彙及進一步發現相關資料有所幫助。
五、部份受訪者對檢索結果重質不重量
在近似字串檢索系統中,雖然比原先預期找到的資料越多,對檢索結果的滿意度越高,但在欄位式檢索系統中則無此關連。在欄位式檢索系統中,受訪者能否精確表達檢索條件的情形約各佔一半,而不管能否精確表達,都沒有影響此結果。由於調查中發現,找到資料的情形越好,受訪者滿意度越高。這兩個結果顯示,部份使用者較重視檢索結果的品質,而比較不重視數量。此點似可印證一般的印象,認為部份使用者較重視查準率,比較不在意查全率。
六、在理想的檢索環境下,相關詞提示與相關詞回饋比用模糊搜尋直接查詢資料庫的成效較佳
相關詞提示與相關詞回饋的比對模式較符合使用者對檢索結果的預期,經由查全率與查準率的試驗,其平均的效果也較模糊搜尋為佳。相關詞提示有很高的查準率,不僅符合上述部份使用者的需求,也沒有因此傷害到查全率。而相關詞回饋若在較多詞彙可供回饋的情況下,也有不錯的表現,惟若可供回饋的詞彙個數太少,則會降低其查全率。
本文僅對線上公用目錄系統過去較為薄弱的功能提供改進方案,
未來線上公用目錄系統仍有需要繼續擴充功能的地方,如資訊過濾(使用者可自動收到符合其興趣的新書通報)[47]、多資料庫查詢(例如,以Z39.50資訊檢索標準同時查詢多個資料庫)[48]
等服務。在近似字串檢索系統方面,可擴充比對欄位,將包含標題詞等主題性資料納進來,或運用索引典之輔助,以達到較高程度的主題檢索(subject
searching)或語意檢索(semantic
retrieval)的功能。除此之外,也可繼續發展適合回溯性資料的檢索方法,例如經OCR(Optical
Character Recognition)辨認處理而含有雜訊的回溯性文件
[49-50] 。這些功能或技術將有助於建構數位化程度更高的館藏,使圖書館的服務更具時間與空間的彈性,滿足更多的使用者需求。
誌謝
本文的完成,要感謝國科會(NSC-87-2415-H-030-006)與輔仁大學的資助,以及張淳淳、游光昭、吳美美、朱則剛、黃士銘等教授給予的寶貴意見,還有輔大圖資系、所多位同學的幫忙,特此致謝。