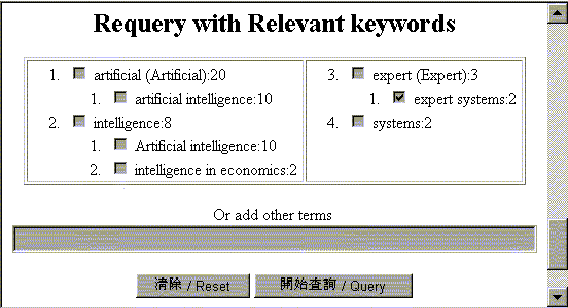
Figure 1. An example from
bibliographic database for term relevance feedback.
曾元顯
Yuen-Hsien Tseng
Associate Professor
Department of Library and Information Science
Fu Jen Catholic University
Email: tseng@blue.lins.fju.edu.tw
http://blue.lins.fju.edu.tw/~tseng/papers/solvoc/solvoc.htm
June. 15, 1998
Accessed times
Abstract
One of the major causes of search
failures in information retrieval systems is vocabulary mismatch.
This paper presents a solution to the vocabulary problem through
two strategies known as term suggestion (TS) and term relevance
feedback (TRF). In TS, collection-specific terms are extracted
from the text collection. These terms and their frequencies constitute
the keyword database for suggesting terms in response to users'
queries. One effect of this term suggestion is that it functions
as a dynamic directory if the query is a general term that contains
broad meaning. In term relevance feedback, terms extracted from
the top-ranked documents retrieved from the previous query are
shown to users for relevance feedback. This kind of local TRF
expands users' search vocabularies
and guides users in search directions closer to their goals. In
our experiment, interactive TS provides very high precision rate
while achieving similar recall rate as n-gram matching. Local
TRF achieves improvement in both precision and recall rate in
full-text News database and degrades slightly in recall rate in
bibliographic database due to the very limited source of information
for feedback. In terms of Rijsbergen's
combined measure of recall and precision, both TS and TRF achieve
better performance than n-gram matching, which implies that the
greater improvement in precision rate compensates the slightly
degradation in recall rate for TS and TRF. We conclude that both
TS and TRF provide users with richer guidance and more predictable
results than n-gram matching alone.
Keywords:
interactive query expansion,
relevance feedback, term suggestion, performance evaluation, information
retrieval
1. Introduction
Users of today's
information retrieval systems often expect that information can
be found faster and easier. However they may not have the skill
to search effectively. Although advanced retrieval models such
as vector space model or probability mode with document ranking
capability have made searching more easier, librarians or experienced
users used to Boolean searching have seen these systems more of
a black box, with the system, not the user, doing most of the
work [1]. Novice or casual users may desire a retrieval system
with rich user guidance, while domain experts or experienced users
may wish a reliable and predictable retrieval system to work with.
Suggestions for further searching and facilities for providing
users more control over the search process may be what is really
needed, especially when search failures occur.
The large volume of ever-increasing
information poses another problem. Excessive results often return
from a simple query. Users seem have little patience in inspecting
the results in the next page, partly because of another waiting
for a "less relevant"
page. Thus the challenge is to design a retrieval system with
high precision rate while maintaining sufficient recall rate for
the benefits of most users.
In this paper, we seek to provide
solutions to the above problems observed in our past experience
with a retrieval system we have been developing. The information
retrieval system is based on n-gram indexing model and vector
space retrieval model. So far it supports natural language-like
queries, fuzzy matching, document ranking, term suggestion and
term relevance feedback. It has been applied since December 1997
to the Online Public Access Catalog (OPAC) of the library of Fu
Jen Catholic University [2]. The retrieval system has also been
applied to a full-text collection, where documents come from the
online news articles from Central Daily News [3] and China Times
[4].
The distinct features in this system
are term suggestion and term relevance feedback. In term suggestion,
users are shown a ranked list of terms "suggested"
by the system based on the matching of the initial query with
a keyword database. Users can then select appropriate terms to
query the document database. In term relevance feedback, terms
extracted from the top-ranked documents retrieved from the previous
query are shown to users for relevance feedback. This paper will
illustrate their applications and describe an evaluation of their
retrieval effectiveness.
Another features in our retrieval
system are relevance ranking and syntactically approximate matching,
or fuzzy matching in short. Relevance ranking ranks retrieved
documents according to some similarity measurement between queries
and documents. High-similarity documents are placed at the top
of the result set in an attempt to help users locate relevant
documents more easily. Such ranking is enabled by the fuzzy matching
which retrieves documents containing string patterns syntactically
approximate to the query string. Fuzzy matching is a powerful
function to free users from worrying about search failure due
to inexact query expression. However, it is also the main cause
that baffles most users for its complex similarity measurement.
As we will show later, fuzzy matching alone may produce unexpected
results. It is better used in the first-half phase of term suggestion
or term relevance feedback.
The rest of the paper is organized
as follows: In the next section, our approach to term suggestion
and term relevance feedback is described. A number of retrieval
examples is illustrated. In Section 3, we describe the retrieval
experiments and the results. Finally Section 4 concludes the paper.
2. Term Suggestion and
Term Relevance Feedback
One of the major causes of search
failures in information retrieval systems is vocabulary mismatch
[5]. Users often input queries containing terms that do not match
the terms used in the relevant documents. Retrieval failures of
such cases can be effectively alleviated through strategies known
as relevance feedback or query expansion [6-14]. In these strategies,
additional query terms or re-weighted terms are added to the original
query to retrieve more relevant documents. This modification of
the original query can be done by the retrieval system in corporation
with the user interactively.
Relevance feedback can take the
form of document relevance feedback (DRF) or term relevance feedback
(TRF). In DRF, users are asked to judge relevant documents retrieved
from the previous query and resubmit the selected documents to
the system. The system then extracts terms from these documents
for further searching. This kind of relevance feedback is easy
to implement. However, users in this process have no control over
which terms are more appropriate than the others. Besides, the
requirement for judging a document relevant or irrelevant may
place an extra burden on users, especially when documents are
in lengthy full text. Thus in our design, we do not use document
relevance feedback.
In TRF, terms extracted from retrieved
documents are shown in certain order of listing for user selection.
Users then inspect the term list and select those terms related
to their goals for another round of searching. The primary difficulty
in this process is that the system should be able to extract meaningful
terms suitable for perusal. Because Chinese texts have no explicit
word boundaries, TRF for Chinese is not possible without a term
extraction module. To overcome this problem, we used a fast keyword
extraction algorithm [15-16] to extract terms from the search
results. Retrieved documents in the same result page are analyzed.
Keywords or key-phrases whose frequencies exceed a certain threshold
(usually 1 or 2) are extracted and presented to users at the bottom
of the same result page. An example from the results of querying
the bibliographic database is illustrated in Fig. 1, where the
query term is "artificial
intelligence". Another
example from the full-text News database is in Fig. 2, where the
query term is "禽性流行性感冒"
("bird flu").
This kind of local TRF provides users more search terms which
are semantically related to (not necessarily syntactically similar
to) the query terms under the same topic. An example is the term
"expert systems"
in Fig. 1. More examples are in Fig. 2, such as "香港"
(Hong Kong), "禽流感病毒"
(bird flu virus), and "H5N1".
Those who care about how serious the tourism has been affected
might choose the terms "旅遊"
(tourism), "航空"
(air service), "退費"
(refund), and "旅客"
(traveler) for further searching. Thus TRF has the effects of
expanding users' search vocabulary
and of guiding users in search directions closer to their goals.
Figure 1. An example from
bibliographic database for term relevance feedback.

Figure 2. An example from
News database for term relevance feedback.
However, there is a problem with
relevance feedback: If there is no relevant documents retrieved
from the initial query, there may not have relevant terms (or
documents) for feedback. Thus it is important to be able to suggest
terms before queries are submitted to the document database. This
would require the system to have a global term list or keyword
database to present vocabularies related to the initial queries.
Again we applied the fast keyword extraction algorithm for term
extraction. From the bibliographic database of 356000 titles,
we have obtained a keyword database of over 110,000 terms. From
the full-text News database, 65,500 terms are extracted from 13,035
news articles.
With these collection-specific keyword
resources, users can search the document databases directly or
search the keyword databases first and then the document databases
indirectly. By searching the keyword databases first, the system
prompts a ranked list of related terms and their estimated term
frequencies. With the understanding of the real terms stored in
the document database and of their frequency distributions, users
may choose appropriate terms for a more effective searching.
A search example is illustrated
in Fig. 3, where the query is "中經院",
an abbreviation of "中華經濟研究院"
(Chung-Hua Institution for Economic Research, CHIER).
Terms related to the query are retrieved with fuzzy matching based
on vector space retrieval model and n-gram indexing model. They
are sorted by match score (the first column) and then by term
frequency (the third column). Note a relevant item, namely the
full name of CHIER, has been retrieved with very low match score
(the highest score is 1000, standing for exact match). Such low-score
matching may only be possible for these keyword databases, because
each record contains only a few characters or words so that any
character hit or word hit is useful to the query. This result
prompts users more complete terms for searching the document database.
The keyword database has an additional effect that if the query term is too broad, the query results function as a dynamic directory. That is, more specific terms under the category specified by the query are present in the results. From this dynamic directory, users are able to understand the distribution of the collection by inspecting the term frequencies and then choose more appropriate terms for searching, avoiding excessive results by submitting the original query to the document database. The example in Fig. 4 with the query term "history of literature" illustrates this effect.
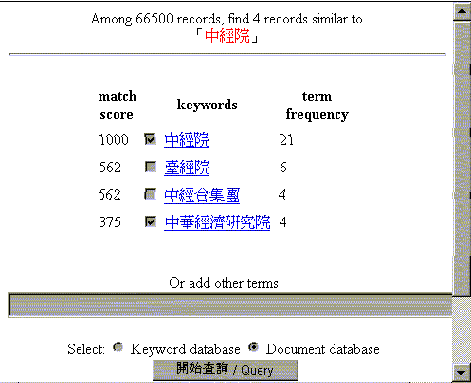
Figure 3. An example for
term suggestion.
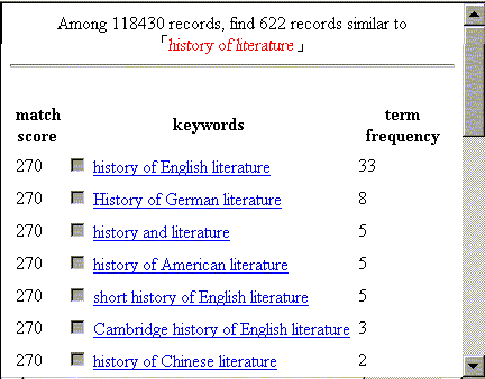
Figure 4. An example illustrating
the effect of "dynamic
directory".
Our system is based on 1-gram and
2-gram indexing and vector space model. This way of n-gram indexing
provides fuzzy matching capability and thus helps locate low-score
terms in keyword databases, such as those found in Fig. 3. If
this matching strategy is applied to the document database with
the terms selected from the keyword database, the results might
be a little unexpected. Again, take Fig. 3 as an example. After
selecting the full name "中華經濟研究院"
and the abbreviation "中經院"
of CHIER for searching the document database, the user may expect
that all the results are related to CHIER. However, Fig. 5 shows
that between the documents containing "中華經濟研究院"
and those containing "中經院",
there are documents in between containing "經濟研究院"
(Institute for Economy Research), "臺灣經濟研究院"
(Taiwan Institute for Economy Research),"經濟研究"
(economy research), and "中央研究院"
(Academia Sinica), because of their higher match scores or even
match scores. Relevant documents are interfered with irrelevant
ones due to the n-gram matching strategy in this case. To overcome
this problem, making the results more predicable, we adopt "term
matching strategy" for
TS and TRF. That is, only documents containing those terms selected
from TS and TRF are retrieved. This might degrade the recall rate,
however. The remedy is to add enough related terms to balance
between precision and recall rates, while maintaining a predictable
result set.
In the next section, we will evaluate
the performance among these three retrieval approaches.

Figure 5. An unexpected effect
of n-gram matching
3. Experimental Results
Three retrieval approaches were
compared for their retrieval effectiveness, namely original query
with n-gram matching (the baseline), term suggestion (TS) with
term matching, and term relevance feedback (TRF) with term matching.
There were two test collections in this experiment. One was an
OPAC bibliographic database with 356,000 titles, the other was
a full-text News database from 13,035 online news articles, as
mentioned previously. To form two sets of queries for each test
collection, seven MS students majored in library and information
science were invited to make up queries. Each of them created
5 queries for each test collection. A number of queries were removed
from the 70 queries, some because they were redundant, others
because there were too little (less than 5) relevant documents
to match the queries. This left 30 queries for each of the test
collection, as shown in Appendix 1. One example of the queries
was "飛碟協會斂財事件"
(The swindle event of UFO Association).
The relevance judgement were made
by the seven students. Only the first N (N=50 in this experiment)
top-ranked documents were judged, in an attempt to reflect the
patterns that users behave when using a ranking retrieval system.
Because the total relevant records for each query is unknown due
to the large volume of the collections, the total number of relevant
records was assumed to be the largest one found by any of these
three retrieval approaches. Appendix 2 lists the precision and
recall rates for each query of the two test databases. In Table
1, average precision and recall rates, and performance improvement
over the baseline approach are listed.
It can be seen that TS with term
matching achieves very high precision rate in both test collections
while maintaining similar recall rate as n-gram matching. For
TRF with term matching, it achieves very high precision rate but
slightly lower recall rate in bibliographic database, and both
slightly higher precision and recall rates in News database. The
reason that local TRF with term matching degrades slightly in
recall rate in bibliographic database is due to the relatively
few texts contained in a page of search results, which includes
at most 20 titles. In average, there are only 9.2 terms for relevance
feedback. However, in the full-text News database, the average
number of terms for feedback is 57, a richer set of search terms
and thus a better performance in both precision and recall rates.
| 0.43 | 0.79 | 0.43 | 0.79 |
|
0.73
+69.2% |
0.80
+2.4% |
0.55
+28.9% |
0.78
-1.1% |
|
0.69
+61.3% |
0.73
-6.6% |
0.45
+6.1% |
0.83
+5.0% |
The experiment can also be evaluated
with a combined measure of precision and recall, E, developed
by van Rijsbergen [17]. The evaluation measure E is defined as:
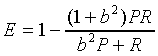
where P stands for precision, R stands
for recall, and b is a measure of the relative importance, to
a user, of recall and precision. For example, b levels of 0.5
indicates that a user was twice as interested in precision as
recall, b levels of 1, indicates that a user was interested in
precision and recall evenly, and b levels of 2 indicates that
a user was twice as interested in recall as precision.
The range of the E measure is between
0 and 1, inclusively. The smaller the value E, the better the
performance in precision and in recall. Because the value of this
E measure is inversely proportional to the performance, we modified
the measure into
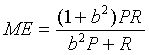
such that 0≦
ME ≦1, and that ME is positively
proportional to the performance. (This is more widely known as F measure.)
With this modification, Table
2 lists the ME values for the three retrieval approaches with
respect to b values at 0.5, 1, and 2.
| b | |||||||
| 0.47 | 0.55 | 0.67 | 0.47 | 0.55 | 0.68 | |
|
0.74
+57.4% |
0.76
+38.2% |
0.79
+17.9% |
0.58
+23.4% |
0.65
+18.2% |
0.72
+5.9% | |
|
0.70
+48.9% |
0.71
+29.1% |
0.72
+7.5% |
0.50
+6.4% |
0.59
+7.3% |
0.71
+4.4% | |
The result in Table 2 shows that
both TS and TRF perform better than n-gram matching alone in terms
of Rijsbergen's combined measure.
This means that the much greater improvement in precision rate
compensates the slightly degradation in recall rate for both TS
and TRF as observed in Table 1.
4. Conclusions
An approach to term suggestion (TS)
and term relevance feedback (TRF) for interactive query expansion
is illustrated. Collection-specific terms are extracted from the
text collection. These terms and their term frequencies constitute
the keyword database for term suggestion. One effect of this term
suggestion is that it functions as a dynamic directory if the
query is a general term that contains broad meaning.
While suggested terms are syntactically
similar to query terms, terms extracted from retrieved documents
are semantically related to the query terms. This kind of local
TRF expands users' search
vocabularies and guides users in search directions closer to their
goals. Thus both TS and TRF with term matching provide richer
user guidance and more predictable results than n-gram matching
alone.
In our performance evaluation experiment,
interactive TS provides high precision rate while achieving similar
recall rate as n-gram matching. Local TRF achieves improvement
in both precision and recall rates in News collection and degrades
slightly in recall rate in bibliographic database due to the very
limited source of information for feedback. However, in terms
of combined measure of precision and recall, both TS and TRF with
term matching perform better than n-gram matching alone. This
means that the much greater improvement in precision rate compensates
the slightly degradation in recall rate for both TS and TRF. Nevertheless,
It is anticipated that a thesaurus with global term-term relationships
and with term matching capability may achieve greater performance
improvement in both precision rate and recall rate, while meeting
users' expectations for predicable
results and for user guidance.
References
Appendix 1: Query sets
for the test collections
The set of queries for the bibliographic database:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The set of queries for the News database:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Appendix 2: Precision and
Recall Rates for the Test Databases
Tables below are the precision and recall rates for the two test databases. The meaning of each column is described as follows:
No : the query identification corresponding to those in Appendix 1.
Ca : No. of retrieved documents by n-gram matching
Cb : No. of relevant documents in the result set by n-gram matching
Da : No. of retrieved documents by TS with term matching
Db : No. of relevant documents in the result set by TS with term matching
Ea : No. of retrieved documents by TRF with term matching
Eb : No. of relevant documents in the result set by TRF with term matching
C-P : precision rate by n-gram matching
D-P : precision rate by TS with term matching
E-P : precision rate by TRF with term matching
C-R : recall rate by n-gram matching
D-R : recall rate by TS with term matching
E-R : recall rate by TRF with term matching
Precision and recall rates of the three retrieval approaches for bibliographic database:
| No | Ca | Cb | Da | Db | Ea | Eb | C-P | D-P | E-P | C-R | D-R | E-R |
| 1 | 50 | 25 | 32 | 28 | 50 | 47 | 0.50 | 0.88 | 0.94 | 0.53 | 0.60 | 1.00 |
| 2 | 50 | 3 | 50 | 14 | 50 | 17 | 0.06 | 0.28 | 0.34 | 0.18 | 0.82 | 1.00 |
| 3 | 50 | 8 | 5 | 2 | 50 | 19 | 0.16 | 0.40 | 0.38 | 0.42 | 0.11 | 1.00 |
| 4 | 50 | 19 | 21 | 16 | 50 | 6 | 0.38 | 0.76 | 0.12 | 1.00 | 0.84 | 0.32 |
| 5 | 50 | 39 | 49 | 49 | 49 | 49 | 0.78 | 1.00 | 1.00 | 0.80 | 1.00 | 1.00 |
| 6 | 50 | 9 | 9 | 5 | 45 | 8 | 0.18 | 0.56 | 0.18 | 1.00 | 0.56 | 0.89 |
| 7 | 50 | 19 | 32 | 18 | 23 | 12 | 0.38 | 0.56 | 0.52 | 1.00 | 0.95 | 0.63 |
| 8 | 50 | 6 | 19 | 5 | 19 | 5 | 0.12 | 0.26 | 0.26 | 1.00 | 0.83 | 0.83 |
| 9 | 50 | 15 | 50 | 12 | 50 | 11 | 0.30 | 0.24 | 0.22 | 1.00 | 0.80 | 0.73 |
| 10 | 14 | 6 | 5 | 5 | 7 | 5 | 0.43 | 1.00 | 0.71 | 1.00 | 0.83 | 0.83 |
| 11 | 50 | 22 | 29 | 29 | 17 | 17 | 0.44 | 1.00 | 1.00 | 0.76 | 1.00 | 0.59 |
| 12 | 50 | 26 | 37 | 37 | 7 | 7 | 0.52 | 1.00 | 1.00 | 0.70 | 1.00 | 0.19 |
| 13 | 50 | 16 | 50 | 48 | 50 | 48 | 0.32 | 0.96 | 0.96 | 0.33 | 1.00 | 1.00 |
| 14 | 50 | 24 | 11 | 11 | 13 | 13 | 0.48 | 1.00 | 1.00 | 1.00 | 0.46 | 0.54 |
| 15 | 50 | 15 | 20 | 20 | 8 | 8 | 0.30 | 1.00 | 1.00 | 0.75 | 1.00 | 0.40 |
| 16 | 50 | 14 | 9 | 9 | 12 | 12 | 0.28 | 1.00 | 1.00 | 1.00 | 0.64 | 0.86 |
| 17 | 50 | 31 | 37 | 37 | 23 | 23 | 0.62 | 1.00 | 1.00 | 0.84 | 1.00 | 0.62 |
| 18 | 43 | 21 | 9 | 9 | 9 | 9 | 0.49 | 1.00 | 1.00 | 1.00 | 0.43 | 0.43 |
| 19 | 50 | 13 | 50 | 30 | 50 | 30 | 0.26 | 0.60 | 0.60 | 0.43 | 1.00 | 1.00 |
| 20 | 50 | 21 | 21 | 20 | 10 | 10 | 0.42 | 0.95 | 1.00 | 1.00 | 0.95 | 0.48 |
| 21 | 50 | 34 | 50 | 40 | 28 | 28 | 0.68 | 0.80 | 1.00 | 0.85 | 1.00 | 0.70 |
| 22 | 50 | 45 | 39 | 39 | 50 | 47 | 0.90 | 1.00 | 0.94 | 0.96 | 0.83 | 1.00 |
| 23 | 50 | 48 | 50 | 50 | 50 | 33 | 0.96 | 1.00 | 0.66 | 0.96 | 1.00 | 0.66 |
| 24 | 50 | 7 | 50 | 13 | 50 | 5 | 0.14 | 0.26 | 0.10 | 0.54 | 1.00 | 0.38 |
| 25 | 50 | 28 | 50 | 39 | 50 | 18 | 0.56 | 0.78 | 0.36 | 0.72 | 1.00 | 0.46 |
| 26 | 50 | 7 | 50 | 13 | 50 | 9 | 0.14 | 0.26 | 0.18 | 0.54 | 1.00 | 0.69 |
| 27 | 50 | 12 | 50 | 11 | 50 | 17 | 0.24 | 0.22 | 0.34 | 0.71 | 0.65 | 1.00 |
| 28 | 50 | 35 | 27 | 27 | 27 | 27 | 0.70 | 1.00 | 1.00 | 1.00 | 0.77 | 0.77 |
| 29 | 50 | 40 | 50 | 35 | 50 | 46 | 0.80 | 0.70 | 0.92 | 0.87 | 0.76 | 1.00 |
| 30 | 28 | 9 | 14 | 4 | 13 | 13 | 0.32 | 0.29 | 1.00 | 0.69 | 0.31 | 1.00 |
Precision and recall rates of the three retrieval approaches for News database:
| No | Ca | Cb | Da | Db | Ea | Eb | C-P | D-P | E-P | C-R | D-R | E-R |
| 1 | 31 | 16 | 47 | 27 | 50 | 27 | 0.52 | 0.57 | 0.54 | 0.59 | 1.00 | 1.00 |
| 2 | 50 | 47 | 50 | 48 | 50 | 50 | 0.94 | 0.96 | 1.00 | 0.94 | 0.96 | 1.00 |
| 3 | 50 | 24 | 50 | 34 | 50 | 42 | 0.48 | 0.68 | 0.84 | 0.57 | 0.81 | 1.00 |
| 4 | 50 | 24 | 32 | 13 | 50 | 21 | 0.48 | 0.41 | 0.42 | 1.00 | 0.54 | 0.88 |
| 5 | 50 | 8 | 50 | 8 | 50 | 11 | 0.16 | 0.16 | 0.22 | 0.73 | 0.73 | 1.00 |
| 6 | 50 | 33 | 50 | 33 | 50 | 35 | 0.66 | 0.66 | 0.70 | 0.94 | 0.94 | 1.00 |
| 7 | 50 | 9 | 50 | 8 | 50 | 14 | 0.18 | 0.16 | 0.28 | 0.64 | 0.57 | 1.00 |
| 8 | 50 | 13 | 50 | 19 | 50 | 13 | 0.26 | 0.38 | 0.26 | 0.68 | 1.00 | 0.68 |
| 9 | 50 | 22 | 50 | 20 | 50 | 15 | 0.44 | 0.40 | 0.30 | 1.00 | 0.91 | 0.68 |
| 10 | 50 | 16 | 50 | 37 | 50 | 17 | 0.32 | 0.74 | 0.34 | 0.43 | 1.00 | 0.46 |
| 11 | 50 | 19 | 18 | 18 | 50 | 12 | 0.38 | 1.00 | 0.24 | 1.00 | 0.95 | 0.63 |
| 12 | 50 | 6 | 50 | 4 | 50 | 6 | 0.12 | 0.08 | 0.12 | 1.00 | 0.67 | 1.00 |
| 13 | 50 | 18 | 22 | 9 | 50 | 19 | 0.36 | 0.41 | 0.38 | 0.95 | 0.47 | 1.00 |
| 14 | 50 | 32 | 31 | 8 | 50 | 17 | 0.64 | 0.26 | 0.34 | 1.00 | 0.25 | 0.53 |
| 15 | 18 | 12 | 5 | 5 | 50 | 14 | 0.67 | 1.00 | 0.28 | 0.86 | 0.36 | 1.00 |
| 16 | 50 | 25 | 50 | 22 | 50 | 21 | 0.50 | 0.44 | 0.42 | 1.00 | 0.88 | 0.84 |
| 17 | 50 | 18 | 50 | 32 | 50 | 38 | 0.36 | 0.64 | 0.76 | 0.47 | 0.84 | 1.00 |
| 18 | 50 | 11 | 50 | 11 | 50 | 15 | 0.22 | 0.22 | 0.30 | 0.73 | 0.73 | 1.00 |
| 19 | 50 | 15 | 2 | 2 | 21 | 15 | 0.30 | 1.00 | 0.71 | 1.00 | 0.13 | 1.00 |
| 20 | 32 | 27 | 11 | 11 | 41 | 36 | 0.84 | 1.00 | 0.88 | 0.75 | 0.31 | 1.00 |
| 21 | 13 | 9 | 9 | 9 | 9 | 7 | 0.69 | 1.00 | 0.78 | 1.00 | 1.00 | 0.78 |
| 22 | 50 | 19 | 50 | 18 | 50 | 18 | 0.38 | 0.36 | 0.36 | 1.00 | 0.95 | 0.95 |
| 23 | 50 | 25 | 50 | 27 | 50 | 16 | 0.50 | 0.54 | 0.32 | 0.93 | 1.00 | 0.59 |
| 24 | 50 | 20 | 50 | 21 | 50 | 15 | 0.40 | 0.42 | 0.30 | 0.95 | 1.00 | 0.71 |
| 25 | 50 | 18 | 50 | 30 | 50 | 19 | 0.36 | 0.60 | 0.38 | 0.60 | 1.00 | 0.63 |
| 26 | 50 | 12 | 50 | 14 | 50 | 19 | 0.24 | 0.28 | 0.38 | 0.63 | 0.74 | 1.00 |
| 27 | 50 | 9 | 50 | 26 | 50 | 8 | 0.18 | 0.52 | 0.16 | 0.35 | 1.00 | 0.31 |
| 28 | 50 | 6 | 50 | 11 | 50 | 4 | 0.12 | 0.22 | 0.08 | 0.55 | 1.00 | 0.36 |
| 29 | 50 | 6 | 23 | 10 | 22 | 12 | 0.12 | 0.43 | 0.55 | 0.50 | 0.83 | 1.00 |
| 30 | 50 | 47 | 50 | 45 | 50 | 45 | 0.94 | 0.90 | 0.90 | 1.00 | 0.96 | 0.96 |